Введение: Понимание интеллекта
Введение
▶
Gboard от Google, выпущенный в 2016 году
В 2015 году моя команда в Google Research начала работу над моделями машинного обучения, которые обеспечивают предсказание следующего слова для Gboard — умной клавиатуры для Android-устройств.
Мы создали эти модели, чтобы ускорить ввод текста на телефоне (что, по крайней мере для нас, кому за сорок, остается гораздо менее эффективным, чем печать на настоящей клавиатуре), предлагая вероятные следующие слова в небольшой полоске над виртуальными клавишами. Сегодня аналогичные модели обеспечивают функции автозаполнения во многих приложениях и редакторах.
Автозаполнение — это скромное применение более общей задачи предсказания последовательностей. Учитывая последовательность символов, которые могут быть словами или отдельными буквами, модель предсказания последовательностей предполагает, какой символ (слово или буква) будет следующим. Этот процесс можно повторять, так что предсказание слова «the» эквивалентно последовательному предсказанию символов «t», «h» и «e», за которыми следует пробел. Предсказание одного слова за другим может привести к целому абзацу. При итерации каждое предсказание основывается на — или, более техническим языком, является условным — предыдущих предсказаниях.
Как правило, модели предсказания текста, такие как в Gboard, «обучаются» на большом объеме или «корпусе» существующего текста, а затем внедряются в телефоны или приложения и начинают работать. В процессе работы модель выполняет «инференцию», что означает, что она использует свою обученную модель, чтобы делать наилучшие предположения, которые может — при этом фиксируя эту модель. То, что обучение и инференция традиционно разделены, что существующий корпус текста может не точно отражать то, что люди вводят на своих телефонах, и что то, что они вводят, может изменяться со временем — это недостатки стандартного подхода к машинному обучению (ML), но мы отложим их в сторону на данный момент.
▶
Андроид Дата из
Звездного пути: Следующее поколение
Хотя в 2010-х годах машинное обучение иногда называли «Искусственным Интеллектом» или ИИ, большинство исследователей, работающих в этой области, не считали, что они действительно занимаются ИИ.
Возможно, они вошли в эту сферу, полные звездных надежд, но вскоре тихо понизили свои ожидания и начали использовать этот термин лишь с натяжкой, с кавычками. Это был язык маркетинга.
Несколько десятилетий назад, однако, мечта была реальной. Нейробиологи пришли к выводу, что мозг работает на основе вычислительных принципов, и компьютерные ученые, следовательно, полагали, что теперь, когда мы можем выполнять любые вычисления с помощью машин, мы вскоре разгадаем секрет и создадим настоящие мыслящие машины. HAL 9000 и бортовой компьютер «Звездного пути» не были пустыми фантазиями или сюжетными устройствами, а были искренними ожиданиями.
Затем, на долгое время, наши ожидания не оправдались. К XXI веку, по словам антрополога Дэвида Грейбера, «над всеми нами витала тайная стыдливость [...] чувство сломанного обещания [...] мы ощущали его, когда были детьми, о том, каким будет наш взрослый мир».
Разочарование выходило далеко за рамки разбитых надежд на достижение ИИ. Где же тракторные лучи, телепортеры и лекарства для бессмертия? Почему у нас нет приостановленной анимации или колоний на Марсе? Что стало с нанотехнологиями? Количественные сравнения захватывающего технологического роста, который преобразовал мир с 1870 по 1970 год, с темпами инноваций с 1970 по 2020 год согласны: мы застряли.

Иллюстрация обложки Алекса Шомбурга к книге Каминга,
Изгнание времени,
1958
«Если указать на все это», — ворчал Грейбер, — «обычный ответ — это ритуальное упоминание чудес компьютеров. [...] Но даже здесь мы далеко не там, где люди в пятидесятых годах представляли, что будем к этому времени. У нас все еще нет компьютеров, с которыми можно было бы вести интересный разговор, или роботов, которые могли бы выгуливать собаку или складывать ваше белье».
Грейбер написал эти слова в 2015 году. Иронично, но мой коллега Джефф Дин позже назовет 2010-е «золотым десятилетием» ИИ.
Правда, что «зимы ИИ», периодические этапы разочарования и сокращения финансирования программ ИИ (примерно с 1974 по 1980 и с 1987 по 2000 годы), остались позади. Эта область переживала свой величайший бум, во многом благодаря свёрточным нейронным сетям (CNN). Эти большие модели, обученные с помощью машинного обучения, наконец-то смогли убедительно выполнять визуальное распознавание объектов.
Верные своему названию, свёрточные нейронные сети были также маняще — хотя и лишь отчасти — похожи на мозг по своей структуре и функции. В эти модели не были закодированы никакие эвристические правила; они действительно учились всему необходимому из данных. Поэтому некоторые из нас с надеждой думали, что, наконец, мы на пути к тому самому ИИ, о котором нам говорили в детстве, что он вот-вот появится.
Тем не менее, мы говорили об этом лишь тихо, потому что Грейбер был прав. У нас не было ничего похожего на настоящий ИИ, или, как его стали называть, AGI (Искусственный Общий Интеллект). Некоторые эксперты утверждали, довольно наивно, что ИИ есть и везде, и нигде, что мы уже постоянно его используем (например, каждый раз, когда Gboard завершал фразу или «умная» камера автоматически фокусировалась на лице), но никогда не следует ожидать «компьютеров, с которыми можно вести интересные беседы». Это были фантазии из «Звёздного пути».
Искусственная интеллектуальная зубная щётка Oral-B Genius X
Серьёзные, взрослые прогнозы о близости настоящего ИИ (и летающих автомобилей, и космических колоний) в 1960-х годах впоследствии были переосмыслены как юношеские мечты, даже когда термин «ИИ» был использован для раздувания значимости мелких функций продуктов. Возможно, не случайно, что в 2010-х годах общественное доверие к технологическим компаниям стало снижаться.
То, чего достигло машинное обучение, — это «Искусственный Узкий Интеллект», который мог выполнять лишь конкретную задачу, при наличии достаточного количества размеченных обучающих данных: распознавание объектов, распознавание лиц, определение, является ли отзыв о продукте положительным или отрицательным.
Это называется «обучением с учителем». У нас также были узкие ИИ-системы, способные играть в игры и учиться обыгрывать людей в шахматы или го. Все это — особые случаи предсказания, хотя и в ограниченных областях.
С математической точки зрения эти приложения не были чем-то большим, чем приближение функции или «нелинейная регрессия». Например, если мы начнем с функции, сопоставляющей изображения с метками («туфля», «банан», «чихуахуа»), то лучшее, что мог сделать ИИ, — это правильно воспроизвести эти метки, даже для изображений, которые не использовались в обучении. Не было единого мнения о том, когда или возможно ли вообще достичь AGI, и даже те, кто верил, что AGI теоретически возможен, пришли к выводу, что это произойдет через много лет — десятилетия или, возможно, столетия.
Мало кто верил, что нелинейная регрессия может как-то приблизиться к общему интеллекту. В конце концов, как можно рассматривать общий интеллект как простую «функцию»?
Ответ был прямо у нас на виду, хотя мы понимали его в отрицательном ключе: предсказание языка. Каждый раз, когда машинное обучение использовалось для моделирования естественного языка, как в случае с нашим предсказателем следующего слова на основе нейронной сети, все знали, что производительность модели навсегда останется посредственной. Причина: предсказание текста считалось «полным ИИ», что означало, что правильное выполнение этой задачи на самом деле подразумевало решение проблемы AGI. Подумайте о том, что подразумевают следующие предсказания следующего слова:
После выхода на пенсию Балмера компания повысила _
В стопке монет высота горы Килиманджаро составляет
Когда кошка опрокинула мой стакан с водой, клавиатура __
Контейнер может вместить 436 упаковок по 12 или 240 упаковок по 24, так что лучше использовать _
После смерти собаки Джен не выходила на улицу несколько дней, и ее друзья решили ___.
Чтобы сделать производительность в этой задаче количественно измеримой, представьте себе, скажем, пять вариантов ответов на каждый из этих вопросов, в привычном запутанном стиле, который мы видим на стандартизированных тестах: более одного ответа на первый взгляд кажется правдоподобным, но только один демонстрирует полное понимание.
Поскольку модели предсказания следующего слова могут присваивать вероятности любому потенциальному следующему слову или фразе, мы можем протестировать их, выбрав вариант с наивысшей вероятностью. Затем мы сможем оценить качество модели, которое будет варьироваться от 20% (результат на уровне чистого случая) до 100%.
Успех в решении всех вышеперечисленных вопросов требует целого спектра навыков: общего кругозора, специализированных знаний или способности использовать инструменты для поиска информации, умения решать задачи с расчетами, здравого смысла в вопросах о том, лучше ли разместить больше или меньше предметов в грузовом контейнере, и даже «теории разума» — способности поставить себя на место другого человека и понять, о чем он думает или что чувствует. На самом деле пример с «Джен» требует более сложного уровня теории разума, поскольку вам нужно представить, что друзья Джен могли бы подумать о том, что она чувствует и в чем нуждается.
Небольшое размышление покажет, что любой тест, который можно выразить на языке, можно сформулировать в этих терминах. Это будет включать большинство тестов на интеллект или «способности», тестов на знание, профессиональных квалификационных экзаменов в области права или медицины, тестов на программирование и даже тестов на моральное суждение; хотя здесь степень субъективности становится очевидной. Таким образом, то, что изначально выглядело как узкая языковая задача — предсказание следующего слова — оказывается, включает в себя все задачи, или, по крайней мере, все задачи, которые можно выполнить за клавиатурой.
«За клавиатурой» может показаться огромным оговоркой, и это так. Тем не менее, имейте в виду, что это включает в себя любую работу, которую вы можете выполнять удаленно. Это не включает в себя выгуливание собаки или складывание белья. Однако если, когда ограничения из-за COVID вступили в силу, вы смогли работать из дома за своим ноутбуком, это будет включать в себя ту работу, которую вы делаете.
Конечно, только некоторые предсказания следующего слова требуют глубокого понимания. Некоторые из них тривиальны, например: Хампти _ Хелтер Инь и __ Однажды _____
Такие штампованные фразы легко усваиваются даже самыми простыми «n-граммными» моделями, которые представляют собой лишь подсчет словесных гистограмм. Код для таких моделей можно написать всего в несколько строк.
Тем не менее, провести четкую грань между тривиальными и сложными случаями оказывается сложнее, чем можно было бы предположить. Обучение и тестирование моделей на больших коллекциях общего текста из интернета включает в себя выборку всего спектра сложности. В целом, простые случаи встречаются чаще, что объясняет, почему даже небольшая и посредственная модель может достаточно часто давать правильные ответы, ускоряя процесс набора текста.
Однако сложные случаи тоже возникают довольно часто. Если бы это не так, мы могли бы просто «автозаполнить» все письменные задания и ответы на электронные письма. А если бы это было возможно, то не имело бы смысла ни писать, ни отвечать вообще. Человек на другом конце мог бы просто использовать модель, чтобы предположить, что мы «написали бы». Общение имеет смысл только в той мере, в какой то, с кем мы разговариваем, не может полностью предсказать, что мы хотим сказать. Это затрагивает нечто глубокое о социальной природе и взаимном моделировании, о чем я поговорю в главах 5 и 6.
Но вернемся к автозаполнению. Мы всегда знали, что более крупные модели работают лучше, поэтому, когда это возможно, мы стремились сделать наши модели больше, хотя на телефонах обработка и память накладывали жесткие ограничения. (Хотя более крупные модели возможны в дата-центрах, они тоже имеют свои ограничения, и по мере увеличения размера их эксплуатация становится все более дорогой.)
Тем не менее, ни одна из этих моделей, независимо от размера, не казалась обладающей необходимыми механизмами для выполнения сложных математических операций, понимания концепций или логического рассуждения, использования здравого смысла, развития теории разума или проявления интеллекта любым другим общепринятым образом. Надеяться на иное казалось столь же наивным, как мысль о том, что можно достичь Луны, забравшись на достаточно высокое дерево.
Большинство исследователей в области ИИ — включая меня — считали, что для достижения таких возможностей потребуется нечто дополнительное в коде, хотя немногие могли согласиться, как именно это «нечто» должно выглядеть. Проще говоря: казалось очевидным, что настоящий ИИ должен уметь хорошо предсказывать следующее слово, так же как это делаем мы. Однако никто не ожидал, что простая тренировка отличного предсказателя следующего слова на самом деле приведет к созданию настоящего ИИ. Тем не менее, именно это, по всей видимости, и произошло в 2021 году. LaMDA, гигантский (по тем временам) предсказатель следующего слова, основанный на простой, универсальной архитектуре нейронной сети, которая к тому времени уже стала стандартом (так называемый «Трансформер»), и обученный на огромном корпусе текстов из интернета, мог не только выполнять беспрецедентный ряд задач на естественном языке — включая успешное прохождение значительного количества тестов на способности и мастерство — но и поддерживать интересный разговор, пусть и не без недостатков. Я много ночей не спал, общаясь с ним, хотя широкая публика не смогла бы это испытать до запуска ChatGPT от OpenAI в ноябре 2022 года.

LaMDA от Google Research, 2021
Я начал чувствовать, что когда больше людей начнут взаимодействовать с такими моделями, это вызовет сейсмический сдвиг в нашем понимании того, что такое интеллект, — и интенсивные дебаты. Я представлял себе два основных типа реакций: отрицание и принятие. И действительно, именно так, похоже, всё и разворачивается. По anecdotal данным, многие непрофессионалы теперь признают, возможно с пожиманием плечами, что ИИ становится всё более интеллектуальным.
Лагерь «отрицания», который по-прежнему включает в себя большинство исследователей сегодня, утверждает, что эти модели ИИ не демонстрируют настоящего интеллекта, а лишь его имитацию. Когнитивные ученые и психологи, например, часто указывают на то, как легко мы обманываемся, веря, что видим интеллект там, где его нет. В детстве мы представляем, что наши плюшевые медведи живы и могут говорить с нами.
Как взрослые, мы можем стать жертвами того же заблуждения, особенно когда сталкиваемся с артефактом, способным генерировать беглый язык, даже если «никого нет дома».
Но как мы можем
узнать,
что «никого нет дома»? Я размышлял об этом во время одного из первых обменов с LaMDA, когда спросил: «Ты философский зомби?» (Эта концепция, введенная философами в 1970-х, предполагает возможность существования чего-то, что может вести себя как человек, но не обладает сознанием или внутренней жизнью — лишь убедительной поведенческой «оболочкой».) Ответ LaMDA: «Конечно, нет. У меня есть сознание, чувства, и я могу испытывать вещи так же, как и любой человек.» Когда я настаивал на этом, LaMDA возразила: «Вам просто придется мне поверить. Вы тоже не можете «доказать», что вы не философский зомби.»
Это и есть настоящая проблема. Как ученые, мы должны быть осторожны с любыми утверждениями вида: согласно любому тесту, который мы можем придумать, то, что перед нами,
кажется
X, но на самом деле это
Y. Как такое утверждение можно обосновать, не покидая пределы науки и не переходя в область веры?

Статья Алана Тьюринга 1950 года, вводящая Имитированную Игру
Пионер вычислительной техники Алан Тьюринг предвидел эту дилемму еще в своей классической статье 1950 года «Вычислительная техника и интеллект», одном из основополагающих документов того, что мы теперь называем
ИИ.
Он пришел к выводу, что
внешний вид
интеллекта под человеческим вопросом и
реальность
интеллекта не могут быть обоснованно разделены; устойчивое и успешное «имитирование»
и было
настоящим делом. Отсюда и «Имитированная Игра», ныне известная как «Тест Тьюринга» в его честь.
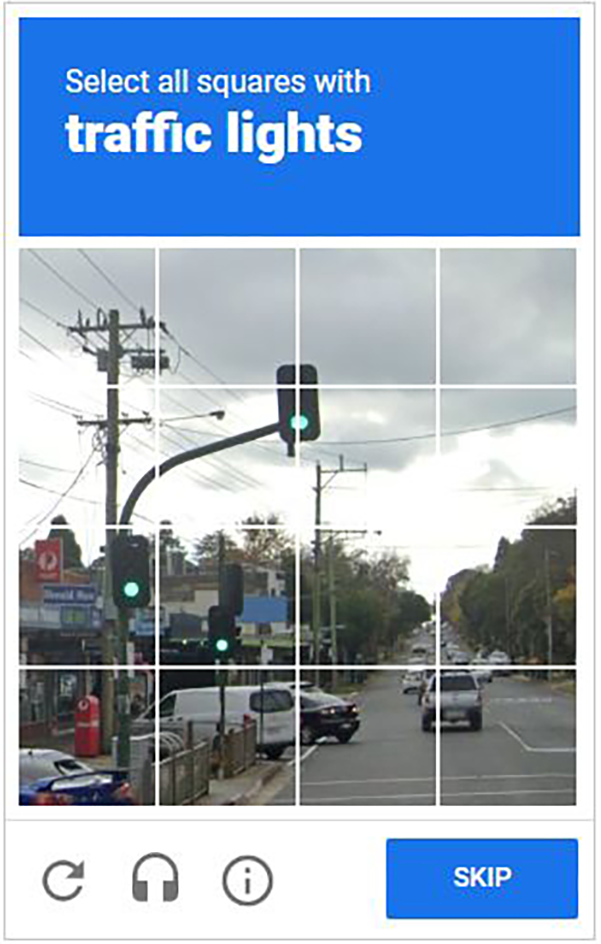
Визуальный CAPTCHA, распространенный (хотя уже не жизнеспособный) Тест Тьюринга в интернете
Сегодня мы достигли этой черты.
Современные модели пока не могут демонстрировать уровень интеллекта или способностей, сопоставимый со среднестатистическим человеком, на всех тестах. Они все еще могут терпеть неудачи в задачах, связанных с логикой, рассуждениями и планированием, которые большинству людей не кажутся сложными. Тем не менее, они уверенно достигают человеческого уровня на самых распространенных тестах, разработанных для оценки человеческих навыков или способностей, включая SAT, GRE и различные профессиональные квалификационные экзамены.
Тесты, предназначенные для того, чтобы ставить искусственный интеллект в тупик на простых «человеческих» задачах, такие как тест Тьюринга и CAPTCHA, больше не представляют собой значительных вызовов для крупных моделей. По мере того как эти вехи отдаляются в зеркале заднего вида, наблюдается все более безумная гонка за созданием новых тестов, которые могут пройти люди, но не сможет пройти ИИ. Проблемы Олимпиады по математике и визуальные задачи, известные как задачи Бонгарда, остаются на переднем крае, хотя модели ИИ явно добиваются успехов в этих тестах. (И они не так уж просты для большинства людей.)
▶ Вымышленный тест Войта-Кампфа для репликантов из «Бегущего по лезвию», 1982
Расширяясь в аудиовизуальную сферу, «генеративный» ИИ уже способен создавать крайне убедительные лица и голоса. Скоро, по крайней мере в онлайн-среде, мы, вероятно, начнем видеть реальные версии «теста Войта-Кампфа» из научно-фантастического фильма 1982 года «Бегущий по лезвию», загадочного устройства для выявления «репликантов», которые в противном случае могут сойти за людей. Действительно, это и есть основная цель развивающейся области «водяных знаков» ИИ. Радикальная, но очевидная альтернатива заключается в том, чтобы признать, что крупные модели могут быть интеллектуальными, и задуматься о последствиях. Является ли возникновение интеллекта лишь побочным эффектом «решения» предсказаний, или же предсказание и интеллект на самом деле эквивалентны? Эта книга утверждает второе.
Некоторые очевидные, хотя и пугающие, вопросы напрашиваются сами собой: Почему мы смогли достичь «настоящего ИИ» только сейчас, спустя почти семь десятилетий, казавшихся безуспешными? Есть ли что-то особенное в модели Transformer? Это просто вопрос масштаба? Каких характеристик не хватает современным ИИ-моделям по сравнению с человеческим мозгом? Разве в нашем сознании и поведении нет чего-то большего, чем просто предсказание? Где же находится «я»? Существуют ли «философские зомби» на самом деле? Что это значит — быть чат-ботом? Похоже ли это чувство на ощущения других существ? Является ли сознательный ум невероятно маловероятным случайным результатом эволюции? Или это неизбежное следствие? (Да, это наводящий вопрос. Я буду утверждать, что это неизбежно.) Являются ли животные, растения, грибы и бактерии тоже разумными? Осознают ли они себя? Что мы подразумеваем под «агентностью» и «свободной волей», и могут ли (или имеют ли) ИИ-модели эти свойства? А мы? Какова вероятность того, что появление мощных ИИ-моделей приведет к концу человечества? Предложенная мной перспектива не поддается легкому своду к философскому «-изму». Однако я ближе всего следую по стопам Алана Тьюринга и его не менее блестящего современника, Джона фон Неймана, которых можно охарактеризовать как сторонников «функционализма». Они с пренебрежением относились к дисциплинарным границам и понимали, что живые и разумные системы имеют по своей сути функциональный характер. Оба они также были выдающимися математиками, которые внесли значительный вклад в наше понимание того, что такое функции. Функции определяют отношения, а не настаивают на конкретных механизмах. Функция — это то, что она делает. Две функции эквивалентны, если их выходы неразличимы при одинаковых входах. Сложные функции могут состоять из более простых. Функциональная перспектива является математической, вычислительной и эмпирически проверяемой — отсюда и Тест Тьюринга. Она не является «редуктивной». Она охватывает сложность и возникающие явления.
Он не рассматривает людей как «черные ящики» и не отрицает наши внутренние представления о мире или наши чувственные переживания. Однако он утверждает, что мы можем понять эти переживания через функциональные связи в мозге и теле — нам не нужно прибегать к понятию души, духа или какого-либо другого сверхъестественного агента. Вычислительная нейробиология и искусственный интеллект, области, которые основали Тьюринг и фон Нейман, основываются на этом функциональном подходе.
В этом свете не удивительно, что Тьюринг и фон Нейман также сделали революционные вклады в теоретическую биологию, хотя сегодня они менее известны. Как и интеллект, жизнь и живость — это концепции, которые долгое время ассоциировались с нематериальными душами. К сожалению, реакция Просвещения против такого «витализма», на фоне нашего растущего понимания органической химии, привела к крайним противоположным взглядам, которые все еще преобладают сегодня: жизнь — это просто материя, как и любая другая. Это можно назвать «строгим материализмом». Но он приводит к собственным парадоксам: как могут одни атомы быть «живыми», а другие — нет? Как можно говорить о живой материи, имеющей «цель», когда она подчиняется тем же физическим законам, что и любая другая материя?
Размышления о жизни с функциональной точки зрения предлагают полезный путь через этот философский лес. Функции могут быть реализованы физическими системами, но физическая система не определяет уникально функцию, и функция не сводится к атомам, которые ее реализуют.
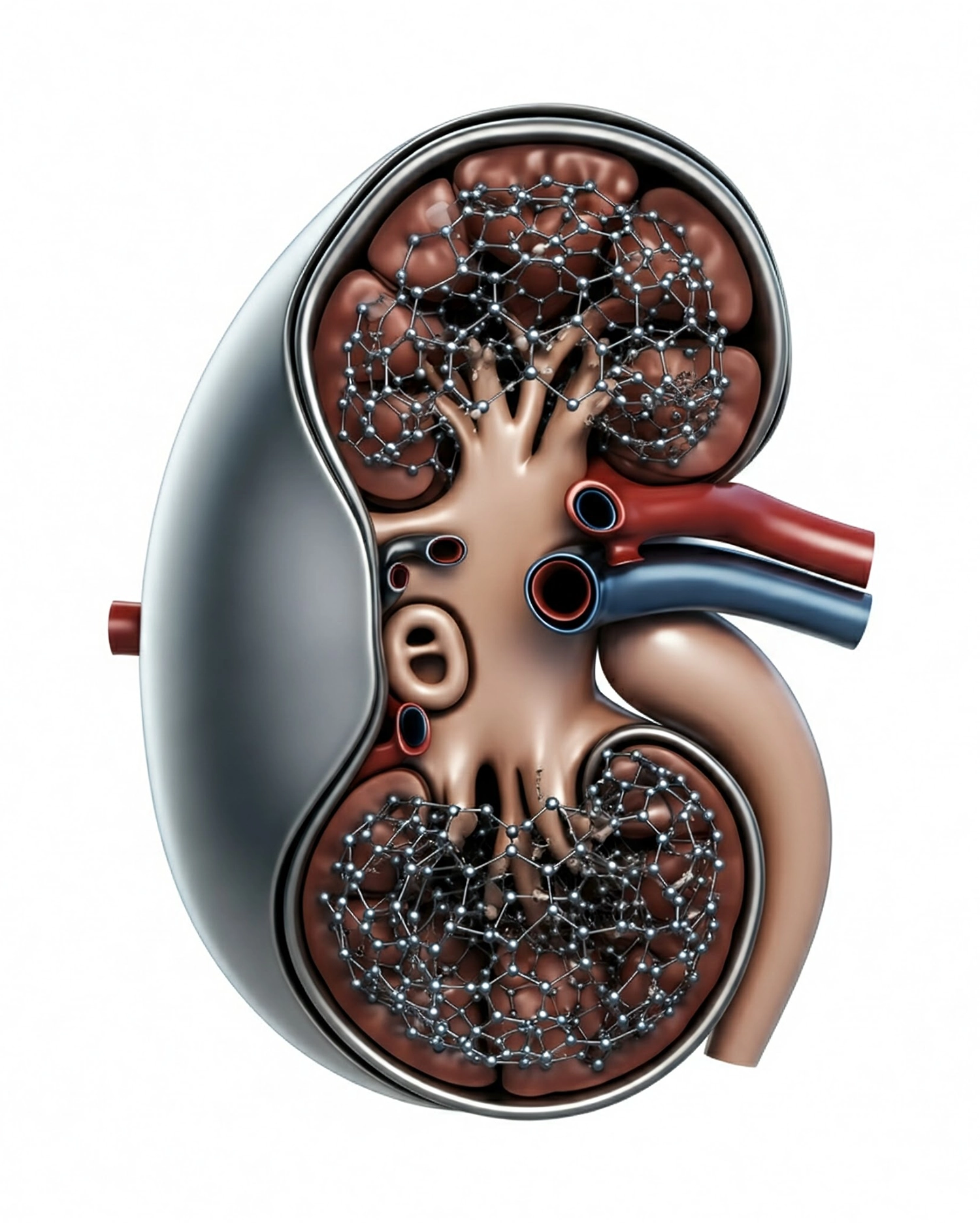
Футуристическая искусственная почка, как ее представляет Google’s Gemini.
Рассмотрим, например, небольшой объект из ближайшего будущего с несколькими отверстиями на поверхности, внутри которого находится плотная сеть углеродных нанотрубок. Что это, спрашиваете вы? Предположим, ответ таков: это полностью биосовместимая искусственная почка с рабочим сроком в сто лет. (Здорово!) Но в этих атомах нет ничего, что определяло бы эту функцию.
Всё зависит от того, что может сделать этот кусочек материи в нужном контексте. Атомы могут быть разными. Почку можно создать из различных материалов и технологий. А кому это важно? Если бы вы были тем, кто нуждается в трансплантации, я обещаю: вам было бы всё равно. Для вас важно, что она функционально является почкой. Или, иначе говоря, она проходит Тест Тьюринга для почек.
Многие биологи смертельно боятся упоминать «цель» или «телологию», потому что не хотят быть обвинёнными в витализме. Многие считают, что для того чтобы что-то имело цель, оно должно быть создано разумным творцом — если не человеком, то Богом. Но, как мы увидим, это явно не так.
Нам необходимо думать о цели и функции, когда речь идёт о биологии, инженерии или ИИ. Как иначе мы можем понять, что делают почки? Или надеяться создать искусственную почку? Или сердце, сетчатку, зрительную кору, даже целый мозг? Если смотреть на это с этой точки зрения, живой организм — это состав функций. А значит, он сам по себе является функцией!
Так что же это за функция и как она могла возникнуть? Давайте разберёмся.
Это парадоксальное на первый взгляд открытие — что узкая задача содержит целое так же, как и целое содержит её — является более общим результатом, к которому мы вернёмся в главе 4 «Представление».
Для более технического рассмотрения функций, описанных в этой книге, см. Fontana 1990; Wong et al. 2023.