Глава 4: Язык и смысл
Обучение
Разминка Пришло время более подробно исследовать внутренние механизмы глубоких нейронных сетей.
Представьте себе перцептрон, обученный распознавать бананы на глаз, во всех их вариациях и ориентациях, на любом фоне. Обычно это подразумевает наличие финального слоя с одним выходом в нейронной сети, содержащего «нейрон банана»; поскольку для такого выходного слоя нам нужно как минимум два нейрона, предположим также, что «нейрон не-банана» активируется в ответ на всё остальное. Супервизированное обучение этой модели будет включать в себя сбор множества изображений либо бананов, либо чего-то другого, каждое из которых помечено одним битом, указывающим, какой из двух нейронов должен активироваться. К концу обучения у нас будет детектор бананов.
Напоминаю из главы 3, что в свёрточной сети более высокие признаки возникают иерархически как комбинации более низкоуровневых признаков. По мере того как активации проходят через более высокие слои сети, представленные признаки становятся всё более инвариантными — то есть, более семантически значимыми.
Я представляю этот процесс немного как разминание теста. Каждый слой нейронной сети обрабатывает свои входные данные, поворачивая их, как шарик теста, в определённом направлении, а затем прижимая, расплющивая их, как будто на столе. Затем следующий слой делает то же самое. Понимание того, как и почему это «разминание данных» достигает каких-либо результатов, потребует более глубокого понимания того, как последовательные слои нейронной сети трансформируют информацию, проходящую через них. Давайте начнём с обратного движения от выходного слоя.
Предположим, что предпоследний слой, непосредственно перед слоем с двумя нейронами, содержит 128 нейронов. В этом слое входные изображения, как говорят, «встраиваются» в 128 измерений. Можно представить активации этих нейронов как координаты точки в 128-мерном «пространстве встраивания».
Думать о высокоразмерных пространствах немного сложно, поскольку мы живём только в трёх измерениях, поэтому давайте развивать немного интуиции.
Указание точки на двумерной поверхности требует двух чисел — например, координат x и y на графике или широты и долготы на карте. Указание точки в трехмерном пространстве требует трех чисел; в прямоугольной комнате, например, это могут быть координаты x и y на полу и высота над полом, z. Так почему бы не указать 128 чисел, определяющих точку в 128 измерениях? Это как 3D, только… больше. Просто представьте, что это 3D. (Все так делают, тайком.)
Ни один из 128 нейронов в слое встраивания не является нейроном банана — иначе не было бы необходимости в дополнительном выходном слое. Тем не менее, большая часть работы по распознаванию бананов, вероятно, уже была выполнена к этому моменту, поскольку выходной нейрон просто получает взвешенное среднее этих 128 нейронных активаций. Веса, связанные с 128 входами нейрона банана, можно рассматривать как «вектор» или направление в 128-мерном пространстве встраивания. Помните, что каждое изображение соответствует точке в этом пространстве встраивания. Чем дальше такая точка находится вдоль «бананового направления», тем сильнее вход к нейрону банана; поэтому мы можем представить вектор, указывающий «в сторону банана».
В качестве альтернативы мы можем представить «гиперплоскость», перпендикулярную банановому вектору. В 3D: представьте гиперплоскость как обычную плоскость, большой плоский лист бумаги. «Банановый вектор» можно визуализировать как стрелу, выходящую прямо из этого листа. Поскольку стрела указывает в сторону бананового «я», мы можем перемещать лист бумаги вдоль стрелы, пока точки, представляющие изображения бананов, не окажутся на дальней стороне, а точки, не относящиеся к бананам, — на ближней стороне. Таким образом, гиперплоскость определяет «порог банановости». Нейрон банана загорится только тогда, когда уровень банановости превысит этот порог; в противном случае, благодаря латеральной инHIBИЦИИ, загорится нейрон «без банана».
Концептуальный набросок гиперплоскости, отделяющей точки, представляющие изображения бананов, от изображений, не содержащих бананы
Это «пороговое преобразование» превращает непрерывное пространство вложений в категорию «да» или «нет». Банан либо есть, либо его нет. Более точно, если банан обнаружен, это обнаружение не зависит от того, было ли значение «бананности» чуть выше порога или значительно выше. Напротив, если активируется нейрон «нет банана», не имеет значения, было ли значение «бананности» чуть ниже порога или значительно ниже.
Вкратце, преобразование от предпоследнего слоя к выходному слою состоит из двух этапов. Сначала каждый выходной нейрон ищет паттерн в предыдущем слое (например, «бананность»), затем нейрон применяет порог, чтобы сделать обнаружение этого паттерна более инвариантным. Эти этапы можно сравнить с двумя шагами замеса: сначала вращение шара теста в определённом направлении, затем его прижатие к твердой поверхности.
Аналогичные основные шаги происходят и в каждом предыдущем слое глубоких нейронных сетей. Все нейроны вычисляют взвешенную сумму активаций в предыдущем слое. И хотя softmax обычно используется только для выходного слоя, все нейроны (искусственные или иные) включают в себя какую-либо форму порогового преобразования или «нелинейности».
Одной из самых распространённых нелинейностей является ReLU, что расшифровывается как «Ректфицированный линейный элемент»; такой нейрон не реагирует, если взвешенная сумма его входов меньше нуля, и в противном случае его активация равна этой взвешенной сумме. Как и softmax (который, напомним, приближает латеральное торможение в реальных нейронах), ReLU вдохновлён основами нейробиологии. Реальные нейроны либо генерируют потенциалы действия, либо нет. Их частота срабатывания, таким образом, либо нулевая, либо положительная; нейрон не может иметь отрицательную реакцию. ReLU — это, по сути, самое простое нелинейное изменение, которое можно внести в линейную «идентичную функцию» f(x) = x, чтобы избежать отрицательного выхода в искусственном нейроне.
Нелинейность ReLU (Ректфицированный Линейный Узел)
Нелинейности, такие как ReLU, играют ключевую роль в глубоком обучении; без них не имело бы смысла создавать нейронную сеть с более чем одним слоем. Взвешенная сумма взвешенных сумм — это просто еще одна взвешенная сумма.
Однако, с наличием нелинейности, последовательные слои больше нельзя заменить эквивалентным единственным слоем. Как упоминалось в предыдущей главе, практически любую функцию можно аппроксимировать, если у вас достаточно нейронов.
Более интуитивно, нелинейности, такие как ReLU, реализуют ограниченную форму инвариантности. Каждый слой в глубокой нейронной сети выполняет ту же задачу, что и выходной слой: ищет паттерн в предыдущем слое и «загорается», если он присутствует. Обнаружение паттернов с помощью одного нейрона является примитивным, так как сводится лишь к взвешенному среднему — форме распознавания, иногда называемой «сопоставлением шаблонов». Тем не менее, нейрон с нелинейностью, такой как ReLU, превращает наличие или отсутствие паттерна в приблизительное «да» или «нет». Это позволяет следующему слою работать с более высокоуровневыми, абстрактными и инвариантными паттернами.
Если углубиться в аналогию с тестом, сопоставление шаблонов или взвешенное среднее активаций нейронов в слое можно сравнить с вращением теста в определённом направлении. На самом деле, математически это почти и есть вращение — просто представьте, что вы вращаете пространство встраивания так, чтобы гиперплоскость оказалась горизонтальной, как столешница.
Применение нелинейности затем «сжимает» данные. Без этого сжатия никакая полезная работа не будет выполнена при повторении процесса — мы просто будем вращать тесто сначала в одну сторону, затем в другую, а потом в третью, что эквивалентно единственному общему вращению. Сжатие между каждым вращением и есть то, что трансформирует тесто. Не существует единственного вращения и сжатия, которые дадут тот же результат, что и сто последовательных вращений и сжатий: тесто развивает глютен, сеть становится лучше в распознавании бананов.
▶
Замешивание теста … в обратном порядке
Ключевое отличие заключается в том, что когда мы замешиваем тесто, наши вращения и сжимания происходят случайным образом. Мы можем начать с муки, воды и соли, но в конце концов эти случайные действия приводят к однородному, клейкому результату. Однако благодаря магии машинного обучения обученная нейронная сеть может сделать противоположное: начиная с «пиксельного теста», в котором смешаны изображения всех видов, она постепенно
раз
смешивает их, пока они не будут четко разделены по категориям. Это как если бы, ориентируя тесто именно так перед каждым нажатием, вы могли бы «размесить» его до тех пор, пока не останется большая куча муки, маленькая кучка соли и лужа воды.
Передача
Если мы уберем последний слой softmax из нашего детектора бананов, его новый выход будет представлять собой 128-мерную точку в пространстве встраивания предыдущего слоя. Учитывая множество разнообразных входных изображений, какие узоры могут образовать эти точки?
Возможно визуализировать такие узоры, хотя нам придется использовать математические приемы, чтобы свести множество измерений к чему-то, что мы можем легко изобразить в 3D или 2D. За эти годы многие научные статьи использовали такие визуализации, однако наиболее впечатляющая из увиденных мною была создана турецко-американским художником Рефиком Анадалом.
▶
Архивные мечты Рефика Анадаля
Скульптура данных ИИ, февраль 2017
Уже будучи признанным художником, Рефик начал свой путь в искусстве ИИ с программы Artists + Machine Intelligence (AMI), которую моя команда и я основали в 2016 году, на заре генеративного ИИ. С тех пор он стал знаменитым. Одним из его первых крупных заказов на искусство ИИ,
Архивные мечты
, стало сотрудничество 2017 года с SALT, художественным и исследовательским учреждением, расположенным в Стамбуле. SALT хранит крупный архив фотографий, архитектурных чертежей, карт, плакатов, переписки и эпhemerы, охватывающий последний век Османской империи и до настоящего времени, и они активно занимаются его цифровизацией. Рефик использовал нейронные сети для генерации встраиваний для 1.
7 миллионов визуальных документов в архиве и созданная комната размером с помещение, погружающая в визуализацию, позволили перемещаться среди всех этих документов, каждый из которых представлен в виде миниатюры, висящей в пустоте. В этом пространстве встраивания визуально схожие объекты группируются вместе, позволяя ощутить архив как галактику с 1,7 миллиона звёзд, расположенных в пространстве, словно по космической системе Дьюи.
Предположим, что Рефик использовал сеть распознавания бананов для генерации своих встраиваний, и архив SALT включал в себя множество изображений бананов. (Кто знает, может, и так.) Мы знаем, что гиперплоскость чётко отделит эти изображения бананов от изображений не-бананов; но как насчёт других фруктов или совершенно других объектов?
Помните, что распознаватель бананов работает, создавая всё более инвариантную иерархию визуальных признаков; выходные нейроны банан/не-банан — это лишь видимая часть подводной части айсберга признаков. Рассмотрим, например, что незрелые и перезрелые бананы выглядят совершенно по-разному. Поэтому для расчёта одного или нескольких нейронов «банан определённой зрелости» в слое встраивания, вероятно, были объединены разные ансамбли признаков, но эта информация о зрелости должна быть отброшена, чтобы создать финальный нейрон банана, инвариантный к зрелости. То же самое будет справедливо для бананов в разных ориентациях или при различных условиях освещения.
Эти наблюдения объясняют «обучение с переносом»: способность переобучить сеть для выполнения связанной задачи, используя гораздо меньше размеченных данных, чем потребовалось бы для обучения с нуля.
Если бы мы хотели, чтобы наша сеть для распознавания бананов обнаруживала только зрелые бананы, например, нам потребовалось бы всего немного подкорректировать последние 128 весов, чтобы исключить незрелые случаи.
▶
Кэролайн Данн демонстрирует набор AIY Vision Kit, продукт Google для экспериментов с объектным распознаванием на основе свёрточных нейронных сетей, в мае 2018 года; обратите внимание, что поскольку груши не входят в набор данных ImageNet, использованный для обучения этой сети, активируются другие визуально связанные нейроны.
Более того, тот же трюк почти так же хорошо сработает для превращения детектора бананов в детектор яблок. Яблоки тоже фрукты, хотя они красные и круглые, а не желтые и длинные. В слое встраивания уже будут нейроны, представляющие свойства яблок, которые могут быть как похожи, так и отличаться от свойств бананов. Таким образом, яблоки можно будет легко обнаружить, просто добавив нейрон яблока в выходной слой рядом с нейроном банана.
Мы могли бы даже обучить веса для этого нейрона яблока на основе одного единственного примера, установив их в зависимости от активаций слоя встраивания в ответ на одно изображение яблока.
(Среднее значение, основанное на нескольких яблоках, было бы лучше, но одно изображение тоже подойдёт.) Сеть впоследствии распознает «ещё одно из этих».
Это более или менее то, что мы делаем во взрослом возрасте, когда учимся о незнакомой категории объектов с одного единственного взгляда. Это называется «обучение с одного примера» и может рассматриваться как особый случай трансферного обучения.
Успех трансферного и обучения с одного примера предполагает, что обучение детектора бананов в основном заключается в том, чтобы научить его видеть в общем смысле — то есть развивать общее чувство перцептивной инвариантности в визуальном мире. Это включает в себя изучение корреляций между пикселями на изображениях, независимо от того, как эти изображения помечены.

Изображения, оптимизированные для выборочной активации определённых нейронов на разных слоях свёрточной нейронной сети. Нейроны на ранних слоях чувствительны к примитивным признакам, таким как края, промежуточные слои реагируют на текстуры и узоры, а более поздние слои распознают семантически значимые объекты и их части; по материалам Олаха, Мордвинцева и Шуберта, 2017.
. Нейроны на ранних уровнях чувствительны к примитивным признакам, таким как края, промежуточные уровни реагируют на текстуры и узоры, а более поздние уровни распознают семантически значимые объекты и их части; по материалам Олаха, Мордвинцева и Шуберта, 2017.

Изображения, оптимизированные для выборочной активации конкретных нейронов на разных уровнях сверточной нейронной сети (CNN). Нейроны на ранних уровнях чувствительны к примитивным признакам, таким как края, промежуточные уровни реагируют на текстуры и узоры, а более поздние уровни распознают семантически значимые объекты и их части; по материалам Олаха, Мордвинцева и Шуберта, 2017.

Изображения, оптимизированные для выборочной активации конкретных нейронов на разных уровнях сверточной нейронной сети (CNN). Нейроны на ранних уровнях чувствительны к примитивным признакам, таким как края, промежуточные уровни реагируют на текстуры и узоры, а более поздние уровни распознают семантически значимые объекты и их части; по материалам Олаха, Мордвинцева и Шуберта, 2017.

Изображения, оптимизированные для выборочной активации конкретных нейронов на разных уровнях сверточной нейронной сети (CNN). Нейроны на ранних уровнях чувствительны к примитивным признакам, таким как края, промежуточные уровни реагируют на текстуры и узоры, а более поздние уровни распознают семантически значимые объекты и их части; по материалам Олаха, Мордвинцева и Шуберта, 2017.
Так нужно ли вообще начинать с детектора бананов? Более того, действительно ли нам необходимо размечать миллиарды изображений на «банан/не банан», чтобы научиться универсальной визуальной инвариантности?
Нет, не нужно. Нейронная сеть может научиться видеть без какой-либо разметки. Это означает, что мы можем полагаться на обучение без учителя, а не на обучение с учителем.
Один из популярных методов без надзора, известный как «маскирование», заключается в том, чтобы зачеркивать случайные части изображений и требовать от сети заполнить, или «восстановить», эти зачерненные участки как можно точнее. Любая нейронная сеть, которая справляется с этой задачей для большого и разнообразного набора изображений, определенно научится выявлять корреляции между пикселями.
Обратите внимание, что это очень похоже на предсказание зачерненных слов или фрагментов текста — именно так обучаются крупные языковые модели! Поэтому в этой книге я использую термины «предсказание» и «моделирование» почти как синонимы. Моделировать данные — значит понимать их структуру, будь то в пространстве, во времени или в обоих случаях; следовательно, это позволяет угадывать невидимые части данных, будь то замаскированные или скрытые в настоящем, или относящиеся к будущему (в этом случае термин «предсказание» наиболее уместен), или даже происходившие, но незамеченные, в прошлом.
Если нейронная сеть научилась успешно восстанавливать (или «предсказывать») недостающие пиксели в корпусе обучающих изображений, это подразумевает, что она также научилась распознавать все, что представлено на этих изображениях — яблоки, пожарные гидранты, сиамских кошек — не только бананы. Она будет знать, как различать фигуру и фон, понимать глубину резкости, распознавать цвета и отличать спелые фрукты от незрелых. Доказательство: если сеть была обучена на изображениях бананов, и вы протестируете ее, зачеркивая половину ранее невидимого изображения банана, она должна убедительно восстановить другую половину. Более того, спелость восстановленной половины должна соответствовать спелости видимой половины.
Это поднимает несколько интересных вопросов, как практических, так и научных.
На практическом уровне в нейронной сети, обученной с использованием неконтролируемого машинного обучения, может скрываться множество знаний, но как мы можем их извлечь? То есть, как превратить эту модель заполнения пикселей в реальный детектор сиамских кошек, бананов или зрелости фруктов?
Мы также можем задуматься о связи между неконтролируемым обучением и нейробиологией. Приятно избавиться от всей этой маркировки «банан/не банан», но затемнение случайных областей в наборе произвольных изображений и обучение модели их заполнению все еще кажется крайне искусственной задачей. Как это связано с тем, как происходит обучение в мозгах?
Зеленый экран
Ограничения трансферного обучения и параллельные ограничения наших собственных мозгов весьма показательны. Если бы сеть, распознающая бананы, была обучена исключительно на фотографиях, сделанных в супермаркетах, а затем мы попытались бы использовать ее для распознавания отдельных лиц, она бы справилась с этой задачей плохо, потому что преобразования, ведущие к слою встраивания, не включали бы усвоенные представления необходимых признаков. Даже если покупатели супермаркетов были бы видны среди изображений «не бананов», соответствующие детали их лиц могли бы быть отброшены на ранних этапах работы сети, потому что эти детали не имеют значения для распознавания бананов — если это хоть какое-то лицо, значит, это не банан, и точка.
Похожий эффект объясняет, почему люди, выросшие в расово однородной среде, часто плохо различают индивидуумов других рас. Мы усваиваем встраивания лиц с раннего возраста, и они чрезвычайно чувствительны — но только в пределах статистического распределения, с которым мы работали. Поэтому так распространены высказывания, обычно считающиеся расистскими, о том, что все люди «иностранной» расы «похожи друг на друга».
Тем не менее, в очень буквальном смысле, если наши мозги не подвергались воздействию «иностранных» лиц в детстве, то для нас это правда. Взрослея, мы можем лишь осознать это ограничение и работать над его преодолением (постоянное улучшение возможно).
Менее оправданно, но та же проблема наблюдается и в свёрточных нейронных сетях, обученных распознавать лица на основе недостаточно разнообразных наборов данных.
Тот же феномен касается и распознавания фонем. Например, в японском языке нет отдельных фонем «r» и «l», что затрудняет взрослым носителям языка различение английских слов «rock» и «lock». Исследования, проведённые ещё в 1980-х и 1990-х годах, показывают, что с момента, когда мозг младенца начинает воспринимать язык — и задолго до того, как он научится говорить — нейронные сети мозга начинают формировать значимые инвариантные представления звуков речи.
Хотя эти инвариантные представления ограничивают то, что может слышать (а затем и говорить) ребёнок, они являются необходимым «каркасом» для обучения более сложным концепциям. В частности, младенцы могут эффективно учить новые слова только после того, как у них сформируется богатое представление необходимых звуков речи на более низком уровне. Взрослые японцы, изучающие английский, могут со временем улучшить свои способности различать «r» и «l», но это требует гораздо больше усилий, чем изучение нового слова на японском, поскольку обучение новому представлению на низком уровне не получает поддержки от этого развивающего каркаса.
Таким образом, обучение — будь то под контролем или нет — в основном сводится к «обучению представлениям», то есть к тому, как внедрять. Используя комбинацию теории и экспериментов в области машинного обучения, физик и исследователь в области ИИ Брис Менар и его коллеги продемонстрировали, что обучение представлениям в многослойных перцептронах является универсальным, независимо от того, как они обучаются.
Можно даже сказать, что обучение — это также обучение тому, как учиться. То есть, как только было освоено подходящее общее внедрение или представление, ассоциация метки с конкретной точкой или областью в пространстве представлений становится тривиальной.
Таким образом, хотя нашим мозгам требуется много времени, чтобы научиться видеть мир и слышать язык, как только мы овладеваем этими представлениями, мы становимся искусными учениками, способными усваивать информацию с одного раза.
Если вам впервые покажут киви, вы сразу сможете узнать этот пушистый фрукт. Перцептрон, обученный на общих задачах восприятия, может сделать то же самое, добавив нейрон киви в выходной слой, обученный за один раз. Это гораздо проще, чем маркировать множество изображений киви (и не-киви) и обучаться на них с нуля.
Если перцептрон обучен заполнять пиксели, а не распознавать бананы, его высокоуровневые слои будут представлять собой общие эмбеддинги, одинаково хорошо описывающие бананы, лица, кошек, киви и все остальное в (немаркированных) обучающих данных. Более того, будут нейроны, отвечающие за спелость фруктов, особенности лиц и породы кошек. Когда изображение кошки, ее цвет глаз будет угадан, если это необходимо, например, если мы его затемнили — в противном случае эти пиксели не могут быть заполнены. Это означает, что скрытое знание о цвете глаз также присутствует, если кошка, случайно, смотрит не в камеру.
Вы можете увидеть, насколько мощным является обучение без учителя. Вот почему в последние годы исследователи стали отходить от старого подхода с контролем. Не только большое количество меток, на которые мы раньше полагались, стало ненужным; они могут даже препятствовать обучению, поскольку обучение модели только на конкретной задаче классификации может позволить изученным представлениям быть менее надежными. Более того, сам процесс маркировки неизбежно вводит дополнительные ошибки и предвзятости, а также требует много труда — в лучшем случае это скучно, а в худшем — эксплуататорски.
Часовня в форме песочных часов «маскированный автоэнкодер» теперь является распространенным способом построения модели перцептрона в стиле обучения без учителя. Начинается с «сетчатого» входного слоя, например, из 512×512 цветных пикселей, последовательность постепенно сужающихся слоев завершается узким местом — скажем, 128 значениями — которые затем снова расширяются в выходной слой такой же формы, как входной.
Входные данные игнорируют замаскированные пиксели, которые могут составлять до семидесяти пяти процентов от общего числа, в то время как выходные данные восстанавливают (или «галлюцинируют») целое изображение. ▶ Демонстрация маскированного автоэнкодера; He и др. 2021. Маскированный автоэнкодер может показаться непримечательным. Если представить его как машину с цифровой камерой, подключенной к входному слою, и экраном, подключенным к выходному слою, он ведет себя как обычный видоискатель. Вы подаете изображение сиамской кошки размером 512×512 пикселей, и на выходе получаете… изображение той же кошки размером 512×512 пикселей, на первый взгляд не отличимое от входного. Однако именно возможность маскирования добавляет волшебства. В дополнение к трем цветовым каналам (красный, зеленый и синий) маскированные автоэнкодеры используют бинарный маскирующий канал, чтобы указать сети, какие пиксели использовать в качестве входных данных, а какие — для дорисовки. Представьте, что вы окунули руку в специальную зеленую краску, которая будет интерпретироваться как эта маска — как в технике «зеленого экрана» в Голливуде, где живых актеров снимают на фоне сплошного зеленого цвета в студии, а затем отснятый материал компонуется в компьютерно-сгенерированную среду. Здесь вы бы помахали своей зеленой рукой перед камерой, и автоэнкодер постарался бы как можно лучше дорисовать эти пиксели. На видоискателе все, что имеет этот оттенок зеленого, было бы невидимо, как будто у автоэнкодера идеальное рентгеновское зрение, позволяющее видеть сквозь вашу руку — даже если вы закрываете большую часть визуального поля. Конечно, этот дорисованный контент — это галлюцинация. Если закрытая вами область небольшая или полностью предсказуема из окружающего контекста, восстановление будет казаться безупречным. Но в общем случае это не так. Если ваша рука частично закрывает тело кошки, у модели нет возможности знать расположение каждого скрытого волоска, поэтому эти детали будут выдуманы. А если вы закроете все, кроме уголка синего неба, восстановленная сцена может иметь мало общего с тем, что на самом деле там находится.
Первая половина нейронной сети начинается с входного изображения и, слой за слоем, сужается до 128 значений на узком месте. Это похоже на классификатор с учителем, лишенный выходного слоя, что говорит о том, что узкое место функционирует как эмбеддинг — и действительно, это так.
Мы также можем интерпретировать слой узкого места как форму сжатия изображения (как описано в главах 1 и 2). Сжатие, в глубоком смысле, тесно связано с языком. Оно извлекает смысл из сигнала, его семантическую суть, на основе которой можно восстановить оригинал, по крайней мере, статистически. Если вы видите достаточно тела кошки, чтобы понять, что это сиамская, то этого знания достаточно, чтобы представить, как будет выглядеть ее голова, где будут ее глаза и что эти глаза будут голубыми. Волоски могут располагаться по-разному в реконструкции, но если это сделано убедительно, судья, столкнувшийся с оригиналом и реконструкцией, не сможет угадать, что есть что. Детали могут варьироваться, но семантическое содержание останется тем же.
Клетка бабушки
Наш зрительный cortex не так уж отличается от перцептрона, но его не обучают, восстанавливая произвольные коллекции частично замаскированных статических изображений. Вместо этого наш мозг подвергается непрерывному потоку «видео» от наших глаз, прерываемому движениями глаз, называемыми саккадами, которые мы совершаем примерно пять раз в секунду. Мозг также контролирует эти саккады, а также ориентацию нашей головы и положение нашего тела, так что поток не является пассивным, а активно генерируется.
Тем не менее, обучение с использованием маскированного автоэнкодера не так уж далеко от нашего опыта, как может показаться. Ретинальная ямка, где мы можем различать достаточно деталей, чтобы читать, едва ли достаточно велика, чтобы разглядеть несколько напечатанных слов. Даже этот участок шумный и дрожащий. Широкое зрительное поле имеет гораздо более низкое разрешение и пересечено кровеносными сосудами.
Это, безусловно, отличается от нашего впечатления о том, что мы видим.
под контролируемыми экспериментальными условиями — смотря на точку одним глазом с нужного расстояния — эти синтетические изображения являются визуальными «метамерами», что означает, что они неотличимы от неискривленной версии этой страницы текста из Моби Дика . Это иллюстрирует относительно небольшую область вокруг фовеа, где мы можем четко различать детали; по материалам Дж. Фримена и Симончелли, 2011 года.
Драматическая серия экспериментов с отслеживанием взгляда, проведенных в нескольких лабораториях с 1970-х до 1990-х годов, это подтверждает. Испытуемый сидит перед экраном, на котором отображается сетка букв. Куда бы ни смотрели его глаза, на экране отображается стабильный текст, но везде остальное — буквы перемешаны. Для наблюдателя весь экран выглядит как неразборчивый хаос. Но если окно четкого текста всего восемнадцать символов в ширину — примерно три символа слева от точки фиксации и пятнадцать справа, в языке, таком как английский, который читается слева направо — то для испытуемого вся страница текста выглядит четкой и стабильной. Это то, что нейробиологи имеют в виду, когда говорят, что мы «галлюцинируем» мир, основываясь на самых скромных сигналах.
С момента, когда мы открываем глаза, вскоре после рождения, и начинаем вращать их, используя наши «внешние глазные мышцы», мы подвергаем наши визуальные системы несупервизированному обучению, подобному тому, что проходит маскированный автоэнкодер. С каждым саккадом у нас есть возможность проверить, выглядит ли ранее неразрешенная часть окружающей среды так, как мы ее предсказали или «дописали» в нашем сознании, и соответственно улучшить нашу модель.
▶
Исследование отслеживания глаз у маленького ребенка, читающего текст; в этом возрасте глаза задерживаются на каждом слове, в то время как более опытные читатели быстро перемещают взгляд по целым фразам и предложениям, используя свои более развитые предсказательные модели текста.
Со временем мы учимся фокусироваться на самых важных местах, где наша неопределенность наибольшая —
это был тигр, пробирающийся сквозь кустарник? — тем самым постоянно привязывая наше восприятие к реальности. Конечно, как только мы отвлекаемся, неопределенность в этом месте начинает снова расти, напоминая о том, как невидимая частица начинает расплываться в квантовой механике.
Зрение —
это не
простой поток сенсорной информации из наших глаз. Скорее, этот поток действует как сигнал для коррекции ошибок.
Зрение —
то, что мы на самом деле
видим —
это реконструкция окружающего нас мира, активно поддерживаемая и ограниченная галлюцинация.
Используя только предсказание, мы быстро научимся мощной модели нашего визуального окружения без контроля. Она будет включать разреженные нейронные представления, обладающие именно теми высокоуровневыми семантическими значениями, которые изучают маскированные автоэнкодеры, которые зафиксировали Хубель и Уизел в зрительной коре кошек, и которые даже были зарегистрированы в мозгах бодрствующих людей.
▶
«Поездка в магазин» — результат обработки видео с использованием алгоритма Deep Dream Алекса Мордвинцева, который изменяет пиксели изображения, частично «галлюцинируя» их значения за счет усиления активности в семантических слоях сверточной нейронной сети; Мордвинцев, Олах и Тыка, 2015. Сузуки и др., 2017, предполагают, что галлюциногенные переживания также являются следствием усиленного предсказания сверху вниз за счет коррекции ошибок снизу вверх.
Я ввел концепцию разреженности в
главе 3
для описания связности в нейронных сетях, как искусственных, так и биологических.
В разреженной сети нейроны соединены лишь с небольшим подмножеством других нейронов; если сеть в целом не очень мала, это ограничение является необходимым для эффективного обучения — и в настоящем мозге физически невозможно, чтобы каждая пара нейронов была соединена. Вся область глубокого обучения может быть понята как исследование разреженных нейронных архитектур, начиная с разделения нейронов на несколько различных слоев.
Идея разреженности может распространяться от соединений к активности. В нейронной сети с разреженной активностью только небольшое подмножество нейронов будет активным (то есть иметь ненулевую активацию) в любой момент времени. Это также является физическим требованием для биологических мозгов, поскольку нейрон расходует значительное количество энергии, когда он активируется. (Вот почему эпилептические эпизоды, когда чрезмерно возбужденные группы нейронов начинают непрерывно активироваться, не могут длиться слишком долго и могут привести к повреждению мозга, так как запасы энергии истощаются, а токсичные побочные продукты накапливаются.)
Даже без таких физических ограничений разреженная активность, похоже, возникает естественным образом в обученных нейронных сетях. В последнем слое классификационной сети причина очевидна: функция softmax заставляет общую активность выходного слоя суммироваться до единицы, в то время как контролируемая классификация поощряет распределение one-hot, где активность доминирует у одного нейрона — крайняя форма разреженности.
Менее очевидно, что разреженность активации возникает и на более ранних слоях. Нелинейности, такие как функция ReLU, естественным образом приводят к разреженности, так как они заменяют то, что в противном случае было бы отрицательной активностью, на нулевую активность, и возникающая "тихость" в одном слое распространяется на последующие слои. Но в более глубоком смысле разреженная активность сопровождается увеличением специфичности реакции каждого нейрона по мере обучения сети.

Разреженность активаций единиц в CNN в ответ на естественное изображение.
Визуализация признаков, вызывающих эти разреженные активации, показывает, что они часто являются смешанными или сложными: нейрон в красном квадрате реагирует на лица собак и цветы; нейрон в зеленом квадрате реагирует на лица людей и кошек; а нейрон в синем квадрате в основном реагирует на лица кошек, что подразумевает разреженное, но не однозначное кодирование на этих промежуточных слоях; Yosinski et al. 2015.

Разреженность активаций единиц в CNN в ответ на естественное изображение. Визуализация признаков, вызывающих эти разреженные активации, показывает, что они часто являются смешанными или сложными: нейрон в красном квадрате реагирует на лица собак и цветы; нейрон в зеленом квадрате реагирует на лица людей и кошек; а нейрон в синем квадрате в основном реагирует на лица кошек, что подразумевает разреженное, но не однозначное кодирование на этих промежуточных слоях; Yosinski et al. 2015.

Разреженность активаций единиц в CNN в ответ на естественное изображение. Визуализация признаков, вызывающих эти разреженные активации, показывает, что они часто являются смешанными или сложными: нейрон в красном квадрате реагирует на лица собак и цветы; нейрон в зеленом квадрате реагирует на лица людей и кошек; а нейрон в синем квадрате в основном реагирует на лица кошек, что подразумевает разреженное, но не однозначное кодирование на этих промежуточных слоях; Yosinski et al. 2015.

Разреженность активаций единиц в CNN в ответ на естественное изображение. Визуализация признаков, вызывающих эти разреженные активации, показывает, что они часто являются смешанными или сложными: нейрон в красном квадрате реагирует на лица собак и цветы; нейрон в зеленом квадрате реагирует на лица людей и кошек; а нейрон в синем квадрате в основном реагирует на лица кошек, что подразумевает разреженное, но не однозначное кодирование на этих промежуточных слоях; Yosinski et al. 2015.

Разреженность активаций единиц в CNN в ответ на естественное изображение.
Визуализация признаков, вызывающих эти разреженные активации, показывает, что они часто смешанные или сложные: нейрон в красном квадрате реагирует на лица собак и цветы; нейрон в зеленом квадрате отвечает на лица людей и кошек; а нейрон в синем квадрате в основном реагирует на лица кошек, что подразумевает разреженное, но не однозначное кодирование на этих промежуточных уровнях; Йосински и др., 2015.
В вашей коре нет единственного нейрона, отвечающего за «банан». Тем не менее, идея о том, что в нашем мозге могут существовать уникальные нейроны, соответствующие очень специфическим восприятиям или воспоминаниям, имеет долгую историю. Термин «нейрон бабушки» был введен в 1967 году с некоторой долей иронии, чтобы обозначить гипотетический нейрон, который активируется только в ответ на образ своей бабушки.
Воспоминание Маргарет Ливингстон о визуальном нейроне, реагирующем на кошек, который после длительных поисков оказался активным только при показе желтой коробки от пленки Kodak, можно интерпретировать как свидетельство существования чего-то, напоминающего нейрон бабушки. Известная статья 2005 года в журнале Nature под названием «Инвариантное визуальное представление одиночными нейронами в человеческом мозге» задокументировала нейрон у человека, который, похоже, реагировал только на Дженнифер Энистон… и другой нейрон, который реагировал только на Дженнифер Энистон и Брэда Питта вместе!
Исследователи также обнаружили нейрон Памелы Андерсон, который реагировал не только на фотографии Андерсон (включая карикатуру на нее), но и на ее имя, написанное текстом — и не реагировал ни на одно другое имя или комбинацию букв, которые они могли найти.
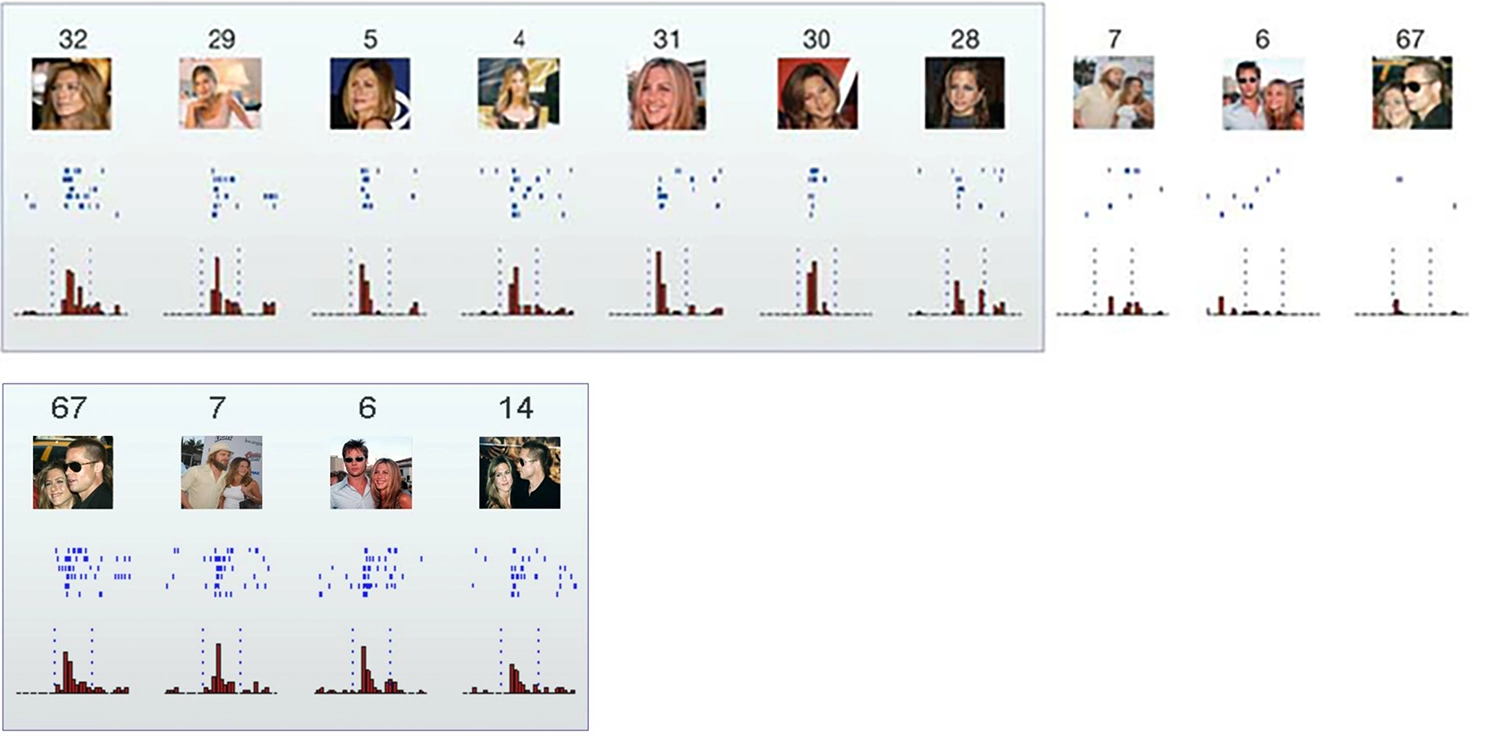
Ответы отдельных нейронов в гиппокампе на выбор из восьмидесяти семи изображений, представленных пациенту. Первый нейрон реагировал на все фотографии Дженнифер Энистон в одиночку, но не (или только очень слабо) на другие знаменитые и незнаменитые лица, достопримечательности, животных или предметы. Нейрон также не реагировал на фотографии Дженнифер Энистон вместе с Брэдом Питтом — хотя другой нейрон (в нижнем ряду) активировался только в ответ на эту пару; Квирога и др., 2005.
Хотя эти выводы и вызывают много вопросов, помните, что никакой процесс контролируемого обучения не заставляет (гипотетический) слой one-hot в вашем мозгу активировать единственный нейрон «банан», «бабушка» или «Памела Андерсон», исключая все остальные. Такие единичные точки отказа сделали бы ваш мозг слишком хрупким. Вы вдруг не сможете узнать свою бабушку, если «ее» нейрон однажды умрет или просто не сработает? И если вы тратите нейроны на такие конкретные концепции, как Дженнифер и Брэд вместе, не рискуете ли вы исчерпать их запас?
Нет: в разреженном распределенном коде, который формируется набором высокоуровневых нейронов (аналогично слою встраивания) без какого-либо контроля или централизации, целый набор нейронов в вашем мозгу активируется в ответ на вашу бабушку, банан или конкретную пару кинозвезд. Даже если только один из десяти тысяч нейронов сработает, это все равно почти десять миллионов нейронов. Так что если несколько из них останутся молчаливыми, это, вероятно, не будет иметь значения. (И хотя код разрежен, он не настолько разрежен, чтобы нейробиолог, исследующий чей-то мозг, показывая ему картинки, никогда не смог бы удачно найти нейрон Памелы, не говоря уже о нейроне Джен и даже о нейроне Джен и Брэд.)
▶ Искусственная нейронная сеть, декодирующая нейронную активность из зрительной коры мозга мыши, способна оценить, на какой кадр видео смотрит мышь; Шнайдер, Ли и Мэтис, 2022.
В качестве бонуса, разреженные распределенные представления значительно эффективнее, чем код one-hot. С 128 нейронами код one-hot может представить только 128 объектов. В разреженном коде, где, скажем, одновременно активируются шестнадцать нейронов, существует около девяноста трех квинтиллионов возможностей.
С увеличением числа нейронов доступные комбинации становятся практически безграничными, даже с учетом значительного количества избыточности.
Конечные причины
Теперь давайте переключимся с восприятия на моторику.
Двигаясь в этом направлении, мы отдаляемся от перцептронов и приближаемся к настоящим существам.
Предположим, нейробиолог регистрирует активность нейронов где-то на сложном пути от зрительной коры животного до его внешних глазных мышц, предполагая, вполне обоснованно, что эти последовательности импульсов (то есть, серии потенциалов действия) представляют собой моторные команды для движения глаз. Как же нейробиолог может «расшифровать» этот поток команд? Ответ, конечно, заключается в одновременном измерении движения глаз и создании модели (в наши дни, вероятно, с использованием искусственной нейронной сети), которая, учитывая последовательности импульсов, может предсказать движение глаз. Если это работает достаточно хорошо, вот и всё — декодер команд для движения глаз, и тем самым доказательство того, что то, что записывается, действительно является командным потоком!
Однако то, что на самом деле создал нейробиолог, можно также интерпретировать как искусственный участок мозга, который — если гипотеза предсказательного мозга верна — выполняет точно такую же задачу предсказания, какую выполняет каждая другая область мозга! «Расшифровка» будет «работать» достаточно хорошо, если большая часть информации, используемой нейронами на нижнем уровне для выполнения их предсказания, захвачена записью, временной масштаб достаточно быстр, чтобы игнорировать обратные связи, модель нейробиолога достаточно мощна, чтобы заменить нижележащую область мозга, и нижележащая область не пытается активно избежать предсказания через динамическую нестабильность и случайность (согласно главе 3).
Короче говоря, учитывая обратные связи, присутствующие повсюду в мозге, интерпретация «командного потока» является произвольной. Если различные области мозга пытаются предсказать друг друга, никакая иерархия не определяет, какая из них отдает команды.
▶ Помещение плодовой мухи в виртуальную реальность, одновременно регистрируя ее мозговую активность, позволяет экспериментаторам создавать искусственные нейронные сети для декодирования аспектов моторной активности животного и его модели мира; Силиг и Джаяраман, 2015.
Нейробиологи и исследователи ИИ могут найти это противоречивым; нам нужно немного нейроанатомии, чтобы понять, почему. Нейроны имеют клеточное тело, расположенное рядом с «дендритами», которые принимают сигналы, и длинный отросток, «аксоны» — я ранее называл эти соединения «проводами» — отправляющий нейронные импульсы к другим нейронам (или мышцам) в других частях мозга или тела. Эти провода могут быть очень длинными. Например, аксон моторного нейрона с клеточным телом в поясничном отделе вашего спинного мозга может простираться до кончика вашего большого пальца ноги, на расстояние более трех футов. (У голубых китов аксоны могут достигать тридцати футов в длину!)
Соблазнительно представить нейроны как маленьких людей, которые «думают» рядом с телом или «головой» и решают, какой сигнал отправить по своему аксонному «хвосту» к цели ниже по течению. Используя философский язык, можно сказать, что мы рассматриваем голову как «агента», а хвост как «пациента», то есть пассивного получателя действий агента.
Идея о том, что цель может быть в ответе, кажется странной, учитывая, где, по-видимому, принимается решение о том, когда произойдет спайк, и в каком направлении этот сигнал спайка, по-видимому, движется. Но, в некотором смысле, хвост вертит собакой.
Пример поможет проиллюстрировать, почему это так. Представьте, что в театре есть пятьдесят свободных мест, которые становятся доступными за пять минут до начала представления, ровно в восемь часов. У гардеробщика есть счетчик. В 7:55 она начинает нажимать на кнопку каждый раз, когда кто-то входит, чтобы закрыть двери, когда счетчик достигнет пятидесяти, или в восемь часов, в зависимости от того, что наступит раньше. Это популярное шоу, поэтому в 7:57 двери закрываются.
Почему двери закрылись? Один ответ, соответствующий тому, что Аристотель называл «эффективной причиной», заключается в том, что пятидесятый человек вошел в дверь. Другой, более глубокий ответ, соответствующий тому, что Аристотель называл «финальной причиной», заключается в том, что театр достиг своей вместимости. Эти «почему» различаются тем, где они локализуют агентность.
Если бы мы были инопланетными исследователями, изучающими театр, мы заметили бы, как один человек проходит мимо, вызывая щелчок, который заставляет контролера закрыть двери. Мы могли бы легко принять этого пятидесятого зрителя за агента, который и закрыл двери. Иными словами, инопланетяне наблюдали бы за «потоком команд», исходящим от зрителя к контролеру.
Но, конечно, ни один из зрителей не проявлял здесь своей воли. Пятидесятый зритель мог даже не заметить, что он последний, кто вошел, и уж точно не считал себя тем, кто закрыл дверь. Чтобы понять, где на самом деле находится агентность, нам нужно отдалиться и взглянуть на всю систему с функциональной или целевой точки зрения, что требует понимания событий, происходивших раньше во времени — причин причин — а также более абстрактных понятий, таких как вместимость театра и описание работы контролера.
Как знает каждый ребенок, который задавал все более раздраженному взрослому вопрос «почему» после каждой попытки объяснения, не существует окончательной причины. Тем не менее, имеет смысл различать механистическую или «как-подобную» причину и целевую, агентную, «окончательную причину».
Вот один из способов отличить их: когда у события есть окончательная причина, разрушение причинной цепи, ведущей к нему, (когда это возможно и в пределах разумного) не приведет к его окончательному разрушению, а лишь заставит его быть достигнутым другими средствами — что подразумевает наличие разумного агента, который осуществляет это «перенаправление причин». Например, если инопланетянин, наблюдающий за театром, решит вмешаться и заберет щелчок, контролер просто пожмет плечами и воспользуется другим методом, чтобы считать людей, входящих в зал, возможно, делая отметки на бумаге или ведя умственный подсчет.
Аналогично, если одна из ваших мышечных клеток работает на пределе, а доступного кислорода недостаточно для удовлетворения энергетических потребностей с помощью аэробного дыхания, она переключится на анаэробный метаболизм — другой набор химических путей, который может высвобождать свободную энергию без кислорода. Клетки адаптивны и находчивы, даже если это всего лишь отдельные мышечные клетки!
Поэтому имеет смысл ответить на вопрос «зачем нашим клеткам нужен кислород?» с точки зрения конечной причины: «потому что он используется для получения свободной энергии». Кислород необходим для аэробного способа достижения этой цели, а получение свободной энергии — критически важная функция клеток, которую необходимо реализовать так или иначе. (К сожалению, в наших клетках возникает кислородный долг через анаэробный путь, так что долго находиться в анаэробном состоянии невозможно, и вам придется отдышаться после интенсивной физической нагрузки.)
Теперь вернемся к нервной системе. Нейронные цепи тоже функциональны, и в сложных нервных системах их функции формируются в процессе обучения. Обучение требует, чтобы сигналы, связывающие активность с ее последствиями, возвращались назад, от цели к источнику; отсюда и алгоритм «обратного распространения» для обучения искусственных нейронных сетей. Как будет обсуждено в главе 7, реальные мозги вряд ли реализуют алгоритм обратного распространения, но любой алгоритм, который они используют, должен каким-то образом включать информацию о « downstream» эффектах, возвращающуюся « upstream» к нейронному механизму, который вызвал эти эффекты, чтобы этот механизм мог быть соответственно изменен. В этом смысле обучение — это сама суть обратной причинности.
Нейробиологи часто не наблюдают непосредственно процесс обучения в электрофизиологических экспериментах, потому что он происходит медленнее, чем электрическая активность в реальном времени. Кроме того, он не так хорошо понят. Мы разобрались, как нейроны генерируют импульсы в 1950-х, но до сих пор спорим о том, как они изменяют свои входные данные и параметры, чтобы научиться определять, когда генерировать импульсы.
Таким образом, наше понимание медленных аспектов нервных систем, проявляющих обратную причинность, значительно отстает от нашего понимания механизмов, лежащих в основе их быстрой, прямой причинности.
Более абстрактно, мы склонны замечать только эффективные причины, а не конечные, так же как инопланетянин, наблюдающий за заполнением театра, мог бы пропустить раннее взаимодействие, когда управляющий театром передал швейцару щелчок и указания о том, когда закрыть двери.
Иногда конечные причины игнорируются по другой, связанной причине: они пахнут телеологией. Действительно, сама идея конечной причины имеет смысл только в контексте целенаправленного поведения. Но, как мы уже видели, биологические (и более широко «интенсиональные») системы характеризуются целями. Мы можем понять их только функционально, что означает принятие конечных причин Аристотеля.
Глупец
Это поднимает тревожный вопрос:
в какой степени мозг действительно «управляет» остальным телом?
Поскольку обучение определяет, что делает каждый нейрон — на какие сигналы он реагирует и какие игнорирует — нейронное тело с длинным аксон, проецирующимся в другую область мозга, не просто существует, чтобы служить области рядом с телом. Это также аванпост, станция прослушивания, чья обученная функция заключается в служении сообществу нейронов на дальнем конце аксона.
Это наиболее очевидно для нейронов в нашей сенсорной периферии, которые мы можем рассматривать как находящиеся в контакте с нашей средой. Датчики давления и температуры в нашей коже передают свои сигналы в «соматосенсорную» кору; светочувствительные клетки в наших сетчатках отправляют информацию в зрительную кору; а чувствительные к вибрации волосковые клетки во внутренних ушах передают информацию в слуховую кору.
Эти клетки явно являются аванпостами для сбора информации. Вы, вероятно, не скажете, что датчик на вашем кончике пальца является «боссом», который отдает команды для управления вашим поведением, а скорее, что это один из многих входов, информирующих ваше поведение.
При определенных обстоятельствах, например, при прикосновении к горячей плите, трудно утверждать, что эти сенсорные нейроны не управляют вами. Ваши интересы как организма лучше всего удовлетворяются максимально быстрой реакцией, что позволяет инициировать действие как можно ближе к источнику сигнала. Поэтому ваш мозг не принимает решения, а просто информируется о том, что вы сделали, уже после того, как это произошло.
▶ Рефлекс отдергивания щупалец улитки
А что насчет мышечной стороны дела? Здесь привычная картина «мозг у руля» кажется наименее спорной. Идея о том, что наш мозг управляет нашими мышцами, кажется очевидной, в то время как мысль о том, что наши мышцы управляют мозгом, на первый взгляд выглядит абсурдной. Как всем известно, мозги умные, а мышцы глупые; в противном случае «мясная голова» могла бы стать синонимом «гения».
На самом деле, сами по себе мышцы кажутся пассивными. Вот почему, если вы получите сильный удар по голове, вы упадете. Пока вы без сознания, ваши мышцы расслабятся и ничего не будут делать. Ваше тело будет похоже на марионетку с обрезанными нитями.
Или нет? Несмотря на свою интуитивную привлекательность, эта точка зрения может быть слишком односторонней. Подумайте о вашем сердце, желудке и кровеносных сосудах — это тоже мышцы. К счастью, они не прекращают сокращаться, когда вы без сознания или спите. Сердце может продолжать биться ритмично довольно долго, даже будучи отключенным от мозга.
▶ Человеческое сердце, поддерживаемое в живом состоянии для процедуры трансплантации, продолжает биться самостоятельно
Действительно, самые ранние подвижные формы жизни, существовавшие как минимум с эдиакарского периода (635–538,8 миллионов лет назад, незадолго до кембрия), вовсе не имели централизованных нервных систем, но, безусловно, обладали мышечной координацией. Мышцы полезны даже для самых простых «сидячих» животных — тех, что прикреплены к камням на морском дне — так как они позволяют выполнять ритмичные насосные движения, чтобы фильтровать морскую воду через свои тела и отсеивать питательные вещества.
Медузы выполняют ритмичные сокращения, свободно плавая, что позволяет им плавать. Координированные колебания могут происходить и на более крупных масштабах, и среди более сложных организмов. Например, гигантские рои некоторых видов светлячков могут светиться почти в унисон, создавая неземное зрелище, напоминающее рождественские огни.
Как синхронность роя светлячков, так и скорость, с которой они могут синхронизироваться, зависят от способности светлячков видеть друг друга. Они могут быстро координироваться — и оставаться скоординированными — потому что видят не только своих ближайших соседей, но и свет более удалённых светлячков, находящихся на другом конце поляны.
Независимо от того, являются ли осцилляторами отдельные мышечные клетки или целые светлячки, координация требует потока информации, но не обязательно подразумевает централизованное управление. Мы можем рассматривать действия отдельных единиц как минимальный вид локального предсказания или завершения паттерна. Каждая единица выравнивает частоту и фазу (т.е. время) своих колебаний с колебаниями соседей. На самом базовом уровне координированное движение объединяет множество сущностей в одно целое.
▶ Пресноводный полип Гидра
«Фазовая синхронизация» — это то, как работает сердце. Перистальтика — координированный манёвр, напоминающий выдавливание тюбика с зубной пастой, который перемещает пищу по кишечнику — также полагается на движущуюся волну сокращений. Децентрализованная координация среди мышечных клеток в органах, таких как сердце и кишечник, а также у животных, таких как медузы и Гидра, частично достигается с помощью «щелевых соединений»: каналов, которые связывают две соседние клетки, позволяя электрической активности одной клетки непосредственно передаваться в другую. Однако быстрая и эффективная синхронизация мышечных сокращений требует более дальнодействующей связи. Децентрализованные нервные сети медуз и Гидры обеспечивают такую дальнюю связь, так же как визуальные системы светлячков позволяют им координироваться через всю поляну.
На самом деле, некоторые из самых ранних нейронных сетей, похоже, вовсе не состоят из отдельных нейронов. «Субэпителиальная нервная сеть» гребневика, древней ветви животной жизни, восходящей к эдиакарскому периоду, представляет собой спаянную или «синцитиальную» сеть нервных волокон, которая эффективно функционирует как неуправляемая магистраль для передачи информации на большие расстояния по всему организму.
Возможно, эти самые ранние нейронные сети лучше всего рассматривать как расширенные внутренние сенсорные системы для мышечных клеток, позволяя им сокращаться синхронно с удалёнными соседями.
▶ Обычный северный гребенник, Bolinopsis infundibulum
Так как же и почему организмы с диффузными нейронными сетями эволюционировали к централизованным мозгам? Вероятный ответ: восприятие внешней среды также полезно для мышечных клеток. Пища, конечно, является важнейшим сигналом из окружающей среды. И практически всё живое избегает вредных стимулов, так же как наши руки отдергиваются от горячей плиты — в общем, используя быструю локальную обратную связь. Химические рецепторы — реализующие хемосенсорные функции, или то, что мы называем «вкусом» — в свою очередь, являются самыми старыми и повсеместными сенсорами окружающей среды, способными различать как приятное, так и неприятное. Не забывайте, что даже бактерии обладают такими сенсорами, ведь в водной среде и на самых малых масштабах плавающие молекулы составляют окружающую среду.
Теперь представьте себе значимость таких рецепторов для животного, которое может как двигаться вперёд, так и поворачиваться благодаря ритмическому сокращению мышц — например, для какого-нибудь червя. В то время как полип коралла прикреплён к одному месту и должен извлекать максимум из того, что его окружает, ползущий червь постоянно принимает решения, которые определяют его будущую среду обитания, а значит, и шансы на выживание. В этом отношении он напоминает плавающую бактерию.
▶
Морские асцидии (Ascidiacea) обладают центральной нервной системой на стадии свободноплавающей личинки, но большую её часть реабсорбируют, когда прикрепляются к субстрату и превращаются в сидячую взрослую форму: нет смысла иметь мозг у животного, которое больше не может двигаться.
В отличие от бактерии, червь длинный и билатерально симметричный, или «билатериан», а не крошечный и цилиндрически симметричный. В результате он может поворачивать влево или вправо, а не просто бежать или катиться — это новшество, критически важное для жизни на суше. Как отметил философ и натуралист Питер Годфри-Смит, «в море животные имеют различные формы тела. На суше все животные — билатериане. Наземных медуз не существует».
Рецепторы на переднем конце билатериан особенно важны, потому что именно они первыми обнаруживают встречу с чем-то вкусным или неприятным. То есть, в отличие от коралла, билатериан движется по миру в определённом направлении, поэтому у него есть передний конец. И, в отличие от точечной бактерии, пространство и время здесь имеют значимое соотношение; можно сказать, что передний конец червя живёт в будущем, а задний — в прошлом. Мышцы по всему телу должны знать о будущем, и те, что справа и слева, будут вести себя по-разному, чтобы отвернуться от вредных объектов и направиться к пище.
▶
Акоэл червь семейства Dakuidae
Таким образом, возникло симбиотическое партнёрство между мышечными клетками и их неподвижными, пространственно расширенными «родственниками» — нервными клетками. Обычно считается, что нейроны взяли под контроль мышечные клетки, но я утверждал, что не менее корректно рассматривать ранние нейроны как каналы информации или даже как сенсорные посты, служащие мышечным клеткам. Изначально нейроны обеспечивали улучшенную координацию на дальние расстояния по всему телу. Но, подключаясь преимущественно к переднему концу животного, мышцы также могли реагировать на любые важные изменения в химических концентрациях в этой области.
Среди билатерий эти реакции нужно было различать с самого начала, не только по типу стимула, но и по его месту действия и расположению мышц. "Ух ты" вправо или "фу" влево должны вызывать сокращение мышц с правой стороны, но не с левой. Диффузной нейронной сети не так просто передать такие пространственно дифференцированные сигналы.
Таким образом, когда мышцы по всему телу начали избирательно соединяться с передним концом животного, возникший узел пространственно организованных нейронов привел к "цефализации": первым проблескам мозга в голове.
Нейромодуляторы
Помимо того, что нужно было развивать простые мозги для обработки немедленного перцептивного ввода, билатерии сразу же столкнулись с необходимостью модулировать свое поведение на временных масштабах, превышающих активации отдельных нейронов или мышц. Даже химотактические бактерии должны вычислять "средний показатель", суммируя или интегрируя то, что они ощущают на протяжении длительного времени, чтобы решить, повышается ли уровень пищи в окружающей среде (в этом случае им следует продолжать плавание) или понижается (в этом случае им следует перевернуться и изменить направление). Билатерии должны были превратить этот интегрированный химический сигнал вокруг головы в внутренний химический сигнал внутри тела, чтобы его могли воспринимать другие нейроны.
Ранние билатерии делали это с помощью нейромодуляторов — химических сигналов, которые накапливаются и постепенно реабсорбируются, влияя на целые популяции нейронов одновременно. В терминах, знакомых из глава 2, мы можем рассматривать эти нейромодуляторы как скрытые переменные состояния (H) с длительными временными масштабами — не постоянные, но более продолжительные, чем любой моментный ввод (X) или действие (O).
Дофамин и серотонин, нейромодуляторы, которые остаются ключевыми для наших мозгов и сегодня, восходят к самым ранним нервным системам билатерий.
«Близкие пищевые сенсоры» в голове червя высвобождают дофамин, что запускает поведение, связанное с кормлением, которое проявляется в бесконечном вращении, позволяющем использовать окружающую среду — так же, как повышенная частота вращения заставляет бактерию оставаться на месте и питаться. Мы можем рассматривать дофамин как сигнал, который преобразует внешний сигнал о наличии пищи в усреднённый внутренний сигнал. Когда уровень дофамина высок, он сообщает мышцам червя, что они должны продолжать вращать животное на месте, чтобы продолжать есть всё, что вкусного находится в непосредственной близости.
▶ Плоский червь C. elegans, питающийся бактериальным «газоном»
Хотя дофамин иногда интерпретируется как сигнал «удовольствия», это не совсем верно. Действительно, нахождение в окружении пищи, вероятно, делает животное более счастливым, чем отсутствие еды, но чаще дофамин лучше понимать как сигнал предсказательной ошибки, даже в этом очень простом контексте. Если вы червь — или любое живое существо — вам нужно предсказывать наличие пищи в вашем будущем окружении. Поэтому вы будете «счастливы», когда будете плыть к пище, что означает, что уровень пищи на вашем переднем конце растёт.
▶ Запись конца 1950-х или начала 1960-х годов, на которой психиатр Роберт Г. Хит интервьюирует пациента с имплантированным электродом для глубокостимуляции мозга, вероятно, вызывая выброс дофамина
Самое подходящее чувство, которое можно ассоциировать с дофамином, вероятно, — это ожидание. Это согласуется с субъективными отчетами человеческих пациентов, которые в серии этически сомнительных экспериментов 1960-х годов были подключены к устройствам, стимулирующим выработку дофамина глубоко в их собственных мозгах. Один пациент, нажимая на кнопку, вызывающую выброс дофамина, объяснял, что «это было похоже на накапливание перед сексуальным оргазмом. Однако он сообщил, что не может достичь оргазмической точки, объясняя, что его частое, иногда беспокойное нажатие на кнопку было попыткой достичь этой точки. Это безуспешное усилие иногда вызывало у него разочарование и в такие моменты он описывал его как «нервное чувство».

Роберт Г. Хит демонстрирует размещение электродов для глубокого стимуляции мозга
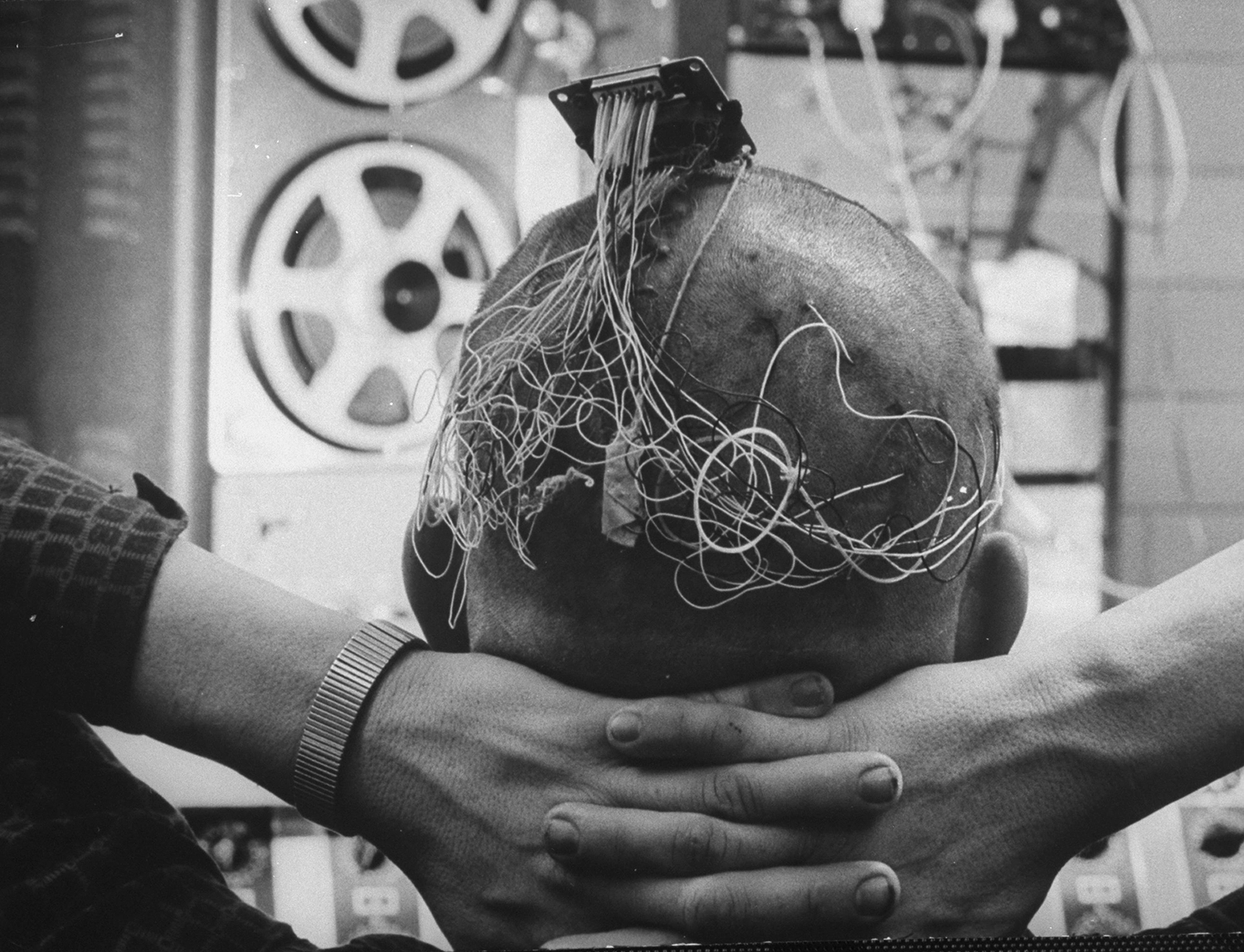
Один из пациентов Хита с несколькими имплантированными электродами
С другой стороны, когда нейроны, производящие дофамин у крыс, уничтожаются, крысы становятся пассивными и умирают от голода, даже если еда «буквально у них под носом».
Если еду положить им в рот, они с удовольствием её съедают, но, сколько бы они ни голодали, без дофамина их не побудит действовать.
Теперь вернитесь на место червя. Если вы понимаете, что ваше предсказание о будущем источнике пищи нарушается снижением уровня еды рядом с вашей головой, вы захотите повернуться. Поворот, даже если он случайный (как у бактерий), поможет вам переориентироваться в сторону, где уровень пищи может снова возрасти — и если это не сработает, просто продолжайте поворачиваться, пока не сработает. В области с максимальным уровнем пищи каждое направление ведет к снижению, поэтому животное будет продолжать поворачиваться (или кувыркаться) на месте, что, как ни странно, является оптимальной стратегией эксплуатации пищи.
Нейроны серотонина выполняют противоположную функцию. Они ощущают пищу в горле животного, а не в окружающей среде. По мере накопления серотонина сообщение становится: «достаточно, я сыт». Эффект дофамина угасает, как и импульс к движению. Наступает постпрандиальная торпор, чтобы лучше переварить пищу.
Таким образом, мы можем грубо охарактеризовать дофамин и серотонин как химические вещества, связанные с «желанием» (дофамин) и «получением» (серотонин). Однако слово «грубо» здесь важно подчеркнуть. И дофамин, и серотонин выполняют сложные и лишь частично понятные функции у животных с большими мозгами.
Снижение уровня дофамина, например, связано не только с «недостатком желания», но и с отсутствием «энергии» или стремления прилагать усилия ради награды — что не совсем одно и то же.
Голодные крысы, лишенные дофамина, не едят из-за отсутствия желания, недостатка энергии или того и другого? Эти вопросы остаются открытыми.
Однако у ранних билатерий дофамин и серотонин влияли на поведение более прямолинейно, предоставляя сглаженные средние значения, доступные другим нейронам, которые приближали ожидаемую пищу и съеденную пищу. Нейроны, которые не находились в непосредственном контакте ни с внешним миром, ни с глоткой, могли соответственно модулировать сигналы, отправляемые к мышцам.
Этот этап развития, похоже, сохранился у аколей — древнего отряда мелких морских червей, который отделился от других животных более 550 миллионов лет назад. С простыми планами тела аколы не имеют кишечника, ни кровеносной, ни дыхательной систем. Они передвигаются (либо плавая, либо ползая между песчинками на морском дне) с помощью "ресничек" — маленьких волосков, покрывающих их поверхность, движения которых контролируются локально.
Помимо распределенной нервной сети, аколы имеют своего рода "мозговую шапку" — скопление нейронов на переднем конце, совпадающее с сенсорами, включая простые глаза. Они могут использовать сложные репертуары поведения, ориентированного на сенсорику, для активной охоты, модулируемой дофамином и серотонином.
Тем не менее, "мозг" кажется не очень организованным. Если одного из этих червей разрезать пополам, то, как и у нейроно-децентрализованной гидры, каждая половина может регенерировать в целое животное. Обмен сигнальными молекулами между мышечными клетками, похоже, координирует процесс формирования и регенерации.
▶ Если от аколы отрезать хвост, передняя часть животного регенерирует новый хвост, в то время как хвост регенерирует две головы, которые затем делятся на два новых аколы.
Самообучение
Животные с простыми распределенными нервными сетями, такие как гидры, показывают мало доказательств обучения в любой форме, которую мог бы распознать экспериментатор по поведению, хотя каждая клетка постоянно регулирует свою биофизику, чтобы оставаться отзывчивой на любые получаемые сигналы — это форма локального обучения.
Это соответствует идее о том, что самые ранние нервные сети служат лишь вторично для восприятия окружающей среды, так как изначально они эволюционировали, чтобы помочь мышцам координировать согласованное движение.
Элементарное поведенческое обучение возникает в тот момент, когда появляется что-то похожее на мозг, потому что в этот момент нейроны в голове начинают совместно адаптироваться к изменяющимся условиям внешнего мира. Каждое соединение или потенциальное соединение между нейронами предлагает параметр — степень связи — которую можно регулировать в зависимости от обстоятельств, даже если «схема проводки» заранее запрограммирована генетически или случайна.
Чтобы понять, почему это так, давайте посмотрим на ситуацию с точки зрения нейрона и представим, что он просто пытается сделать то же самое, что и любое живое существо: предсказать и обеспечить свое собственное существование.
Некоторые аспекты этого предсказания, безусловно, были заложены эволюцией. Например, если дофамин является индикатором близости пищи, нейрон будет пытаться предсказать (и тем самым обеспечить) наличие дофамина, потому что длительное отсутствие дофамина подразумевает, что всё животное будет голодать — что приведет к концу существования этого нейрона, вместе со всеми его клеточными клонами. Даже скромная клетка имеет множество потребностей и желаний, помимо пищи, но без еды нет будущего.
Поэтому, если нейрон сам не выделяет дофамин, но его активность каким-то образом влияет на уровень дофамина в будущем, он будет пытаться активироваться в моменты, которые увеличивают будущий уровень дофамина. Помимо нейромодуляторов, таких как дофамин, входные сигналы нейрона поступают либо от других нейронов, либо, если это сенсорный нейрон, из внешнего источника, такого как свет или вкус. Он может активироваться спонтанно или в ответ на любую комбинацию этих входных сигналов, в зависимости от своих внутренних параметров и степени связи с соседними нейронами. Следовательно, по всей видимости, одной из его целей становится манипуляция своими параметрами так, чтобы, когда нейрон срабатывает, будущий уровень дофамина был максимальным.
Я только что описал базовый алгоритм обучения с подкреплением, в котором дофамин выступает в роли сигнала вознаграждения. Однако по мере усложнения мозга он начал создавать более сложные модели будущего вознаграждения, и, соответственно, у позвоночных животных дофамин, похоже, был переориентирован на поддержку чего-то, что можно назвать более сложным алгоритмом обучения с подкреплением: «обучение с временной разницей» или «TD» обучение.
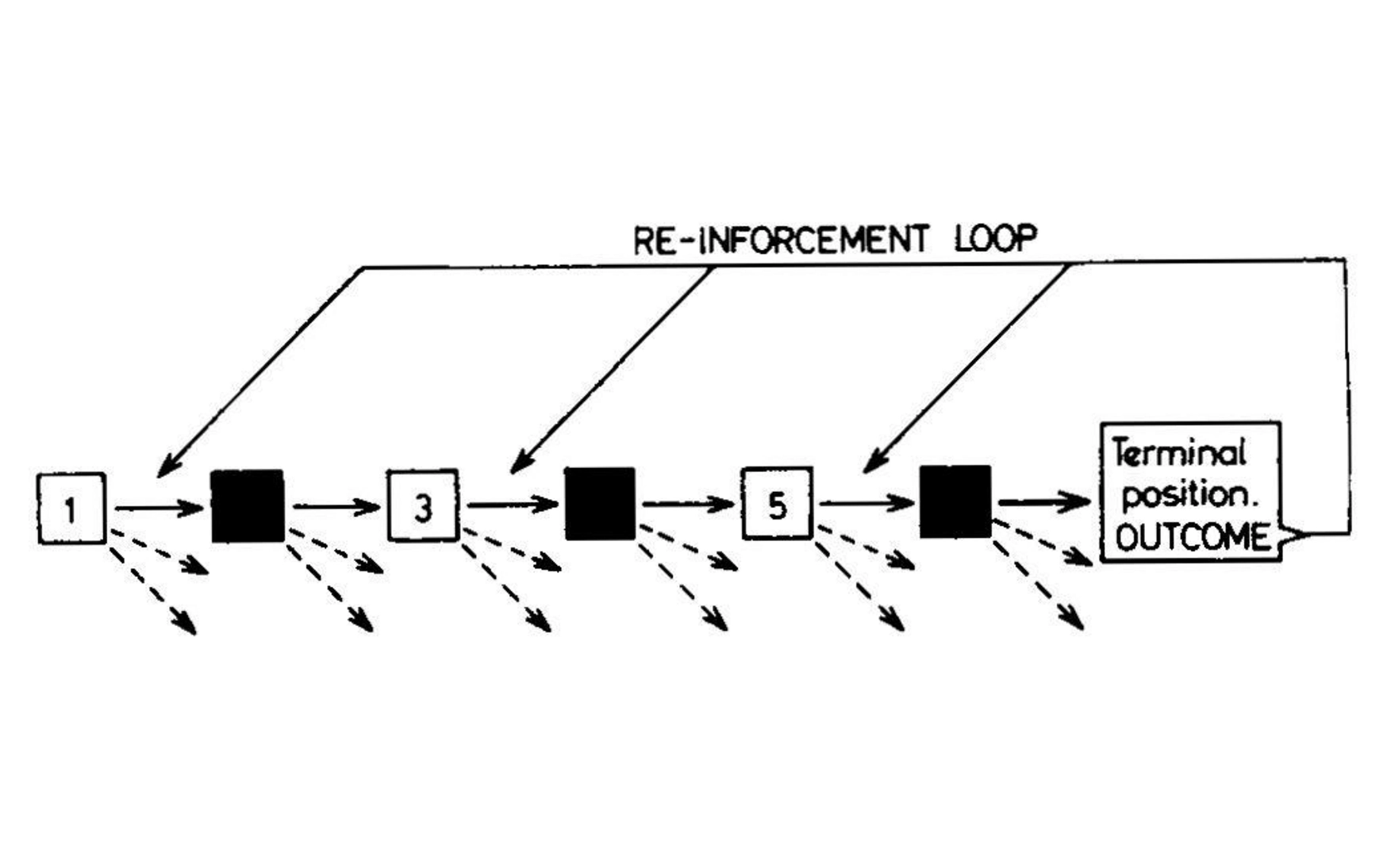
В 1961 году исследователь в области ИИ Дональд Мичи разработал MENACE, обучаемый движок для игры в крестики-нолики, который стал одним из первых алгоритмов обучения с подкреплением. Поскольку у него не было доступа к компьютеру, Мичи реализовал алгоритм с помощью 304 спичечных коробков, представляющих уникальные состояния игрового поля, каждый из которых содержал бусинки, символизирующие текущую наилучшую стратегию; Мичи 1963.

В 1961 году исследователь в области ИИ Дональд Мичи разработал MENACE, обучаемый движок для игры в крестики-нолики, который стал одним из первых алгоритмов обучения с подкреплением. Поскольку у него не было доступа к компьютеру, Мичи реализовал алгоритм с помощью 304 спичечных коробков, представляющих уникальные состояния игрового поля, каждый из которых содержал бусинки, символизирующие текущую наилучшую стратегию; Мичи 1963.
В 1961 году исследователь в области ИИ Дональд Мичи разработал MENACE, обучаемый движок для игры в крестики-нолики, который стал одним из первых алгоритмов обучения с подкреплением. Поскольку у него не было доступа к компьютеру, Мичи реализовал алгоритм с помощью 304 спичечных коробков, представляющих уникальные состояния игрового поля, каждый из которых содержал бусинки, символизирующие текущую наилучшую стратегию; Мичи 1963.
Обучение с временной разницей работает путем постоянного прогнозирования ожидаемого вознаграждения и обновления этой предсказательной модели на основе фактического вознаграждения. Этот метод был изобретен (или, возможно, открыт) Ричардом Саттоном, когда он еще был аспирантом, работая над своей диссертацией по психологии в Университете Массачусетса в Амхерсте в 1980-х годах.
Саттон стремился превратить существующие математические модели Павловского кондиционирования в алгоритм машинного обучения. Проблема заключалась, как он сам выразился, в «обучении предсказанию», то есть в использовании прошлого опыта с частично известной системой для предсказания её будущего поведения.
В стандартном обучении с подкреплением такие предсказания ориентированы на цель. Смысл заключается в том, чтобы получить награду — например, еду или победу в настольной игре. Однако «проблема распределения кредита» усложняет эту задачу: длинная цепочка действий и наблюдений может привести к конечной награде, но установить прямую связь между действием и наградой позволяет агенту научиться только последнему шагу в этой цепочке.
Как выразился Саттон, «в то время как традиционные методы обучения предсказанию распределяют кредит на основе разницы между предсказанными и фактическими результатами, [методы TD обучения] распределяют кредит на основе разницы между временно последовательными предсказаниями».
Используя изменение в оценке будущей награды в качестве сигнала для обучения, становится возможным определить, является ли данное действие хорошим (и, следовательно, его следует укрепить) или плохим (и, следовательно, его следует наказать) до того, как игра будет проиграна или выиграна, или еда будет съедена.
Это может показаться замкнутым кругом, ведь если бы у нас уже была точная модель ожидаемой награды для каждого действия, нам не нужно было бы учиться дальше; почему бы просто не выбрать действие с наивысшей ожидаемой наградой? Однако, как и во многих статистических алгоритмах, разделив проблему на чередующиеся шаги, основанные на различных моделях, эти модели могут поочередно улучшать друг друга, что называется «бустраппингом» — в честь старой пословицы о невозможности поднять себя за собственные шнурки. Здесь же это возможно.
В контексте TD обучения две модели часто описываются как «актер» и «критик»; в современных реализациях модель актера называется «функцией политики», а модель критика, предназначенная для оценки ожидаемой награды, — «функцией ценности».
Эти функции обычно реализуются с помощью нейронных сетей. Критик обучается, сравнивая свои прогнозы с фактическими вознаграждениями, которые он получает, выполняя ходы, предписанные актёром, в то время как актёр совершенствуется, изучая, как выполнять ходы, которые максимизируют ожидаемое вознаграждение согласно критика.
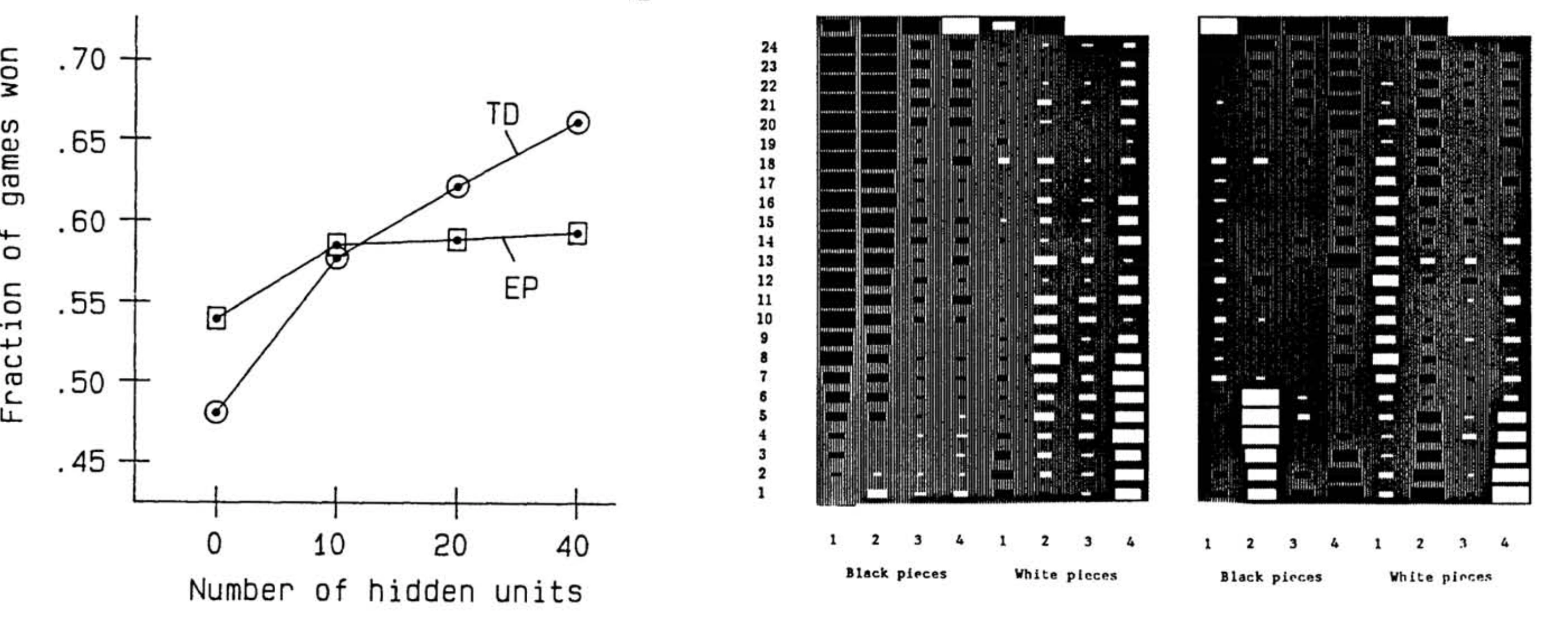
TD-Gammon Джеральда Тесауро, приложение обучения с подкреплением на основе временной разности к игре в нарды, смогло обыграть опытных игроков более чем в половине случаев, когда обученная нейронная сеть содержала более десяти скрытых единиц (или нейронов); Тесауро, 1991.
Система обучения TD в конечном итоге находит способ хорошо выполнять задачи, даже если как актёр, так и критик изначально совершенно наивны и принимают случайные решения — при условии, что задача не слишком сложна и что случайные ходы иногда приносят вознаграждение. Таким образом, эксперимент 1990-х годов, применивший обучение TD к нардам, прошёл с блестящими результатами, хотя применение того же метода к сложным играм изначально потерпело неудачу.
За пределами вознаграждения
Примерно в то же время в Институте физиологии Университета Фрибурга лаборатория Вольфрама Шульца изучала взаимосвязь между моторной функцией и болезнью Паркинсона, которая, как известно, нарушает движение из-за истощения дофамина.
В типичном эксперименте Шульц и его коллеги записывали данные от одиночных дофаминергических нейронов в мозгах макак, пока те выполняли простые моторные задачи, которые им нужно было изучить с помощью Павловского кондиционирования.
Например, жаждущей обезьяне нужно было научиться, какую из двух ручек тянуть в ответ на мигающий свет, чтобы получить глоток сока. Исследователи сделали следующие наблюдения: дофаминовые нейроны обычно активируются с умеренной фоновою частотой. Когда обезьяны впервые наткнулись на действие, приводящее к получению сладкого напитка, частота спайков этих дофаминовых нейронов возросла.
Как только обезьяны поняли связь между визуальным сигналом и наградой, дополнительная дофаминовая реакция перестала возникать в момент получения угощения и стала проявляться раньше — при появлении визуального сигнала. Это совпало с тем, что обезьяны начали облизывать губы, напоминая слюноотделение собак Павлова.
Если после визуального сигнала угощение не подавалось, активность дофаминовых нейронов затем снижалась — то есть они становились менее активными по сравнению с фоновым уровнем.
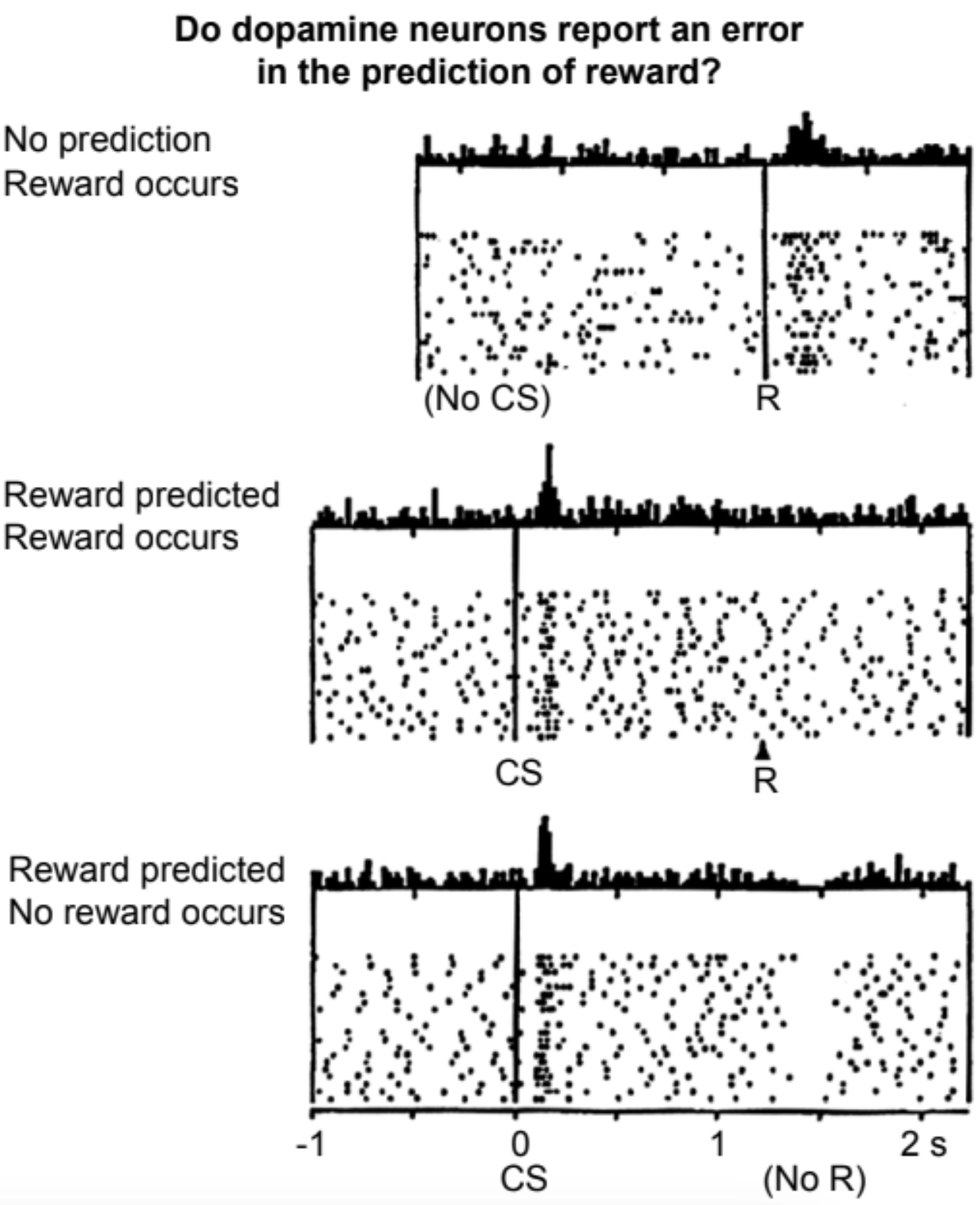
Записи активности дофаминового нейрона при получении неожиданной награды, ожидаемой награды и отсутствии ожидаемой награды; Шульц, Даян и Монтег 1997.
Когда Питер Даян и Рид Монтег, тогдашние постдоки в лаборатории Терри Сейновски в Институте Солка в Сан-Диего, увидели эти результаты группы Шульца, они поняли, что дофамин действует именно как сигнал обучения с временной разницей.
Это сигнал, благодаря которому «критик» мозга говорит «актеру»: пожалуйста, усиливай то поведение, которое ты проявляешь сейчас, потому что я предсказываю, что оно приведет к будущей награде. Долгие последовательности действий, которые в конечном итоге приводят к награде, могут быть изучены таким образом, при этом сигнал TD смещается все раньше и раньше в последовательности по мере прогресса обучения.
Перепрофилирование дофамина из простого сигнала о награде в нечто вроде сигнала обучения с временной разницей может естественным образом следовать из роста структур мозга как «вверх», так и «вниз» от нейронов, выделяющих дофамин. Помните, что даже среди самых ранних билатерий дофамин уже не представляет собой еду, а лишь близлежащую еду. В этом смысле дофамин уже является предсказанием еды, а не наградой за еду сам по себе. Таким образом, предсказание дофамина — это предсказание предсказания еды.
Предсказательная симбиоз между нейронными областями, находящимися выше и ниже дофамина, приведет к тому, что верхние области смогут делать более сложные предсказания (а значит, и долгосрочные прогнозы), действуя как все более утонченный критик или функция ценности. В то же время нижние части становятся все более изощренными актерами или функцией политики, достаточно умными, чтобы учиться делать лучшие ходы, используя эти долгосрочные прогнозы.
Это может помочь объяснить приблизительное соответствие между парадигмой обучения с временными разностями (TD) и, по крайней мере, одной из основных ролей, которую дофамин играет в мозгах позвоночных.
Как и многие примитивные чувства, «что-то хорошее на расстоянии вытянутой руки» — это простой, но полезный сигнал, который червь может напрямую воспринимать через запах, а более крупный мозг, как у нас, может интерпретировать через гораздо более сложный когнитивный процесс. Это полезный сигнал для многих частей мозга, поскольку все они заинтересованы в том, чтобы обеспечить хорошие результаты для организма в целом; именно поэтому сигнализация дофамина сохранялась на протяжении сотен миллионов лет, и его роль оставалась, если не такой же, то по крайней мере узнаваемой на протяжении этих эпох.
Тем не менее, нам следует быть осторожными и не интерпретировать эти экспериментальные результаты о дофамине как доказательство того, что мозг реализует обучение TD, как это сформулировал Саттон. Это не может быть всей историей. Во-первых, у нас есть достаточные доказательства того, что люди, а вероятно, и многие другие животные, являются еще более мощными обучающимися, чем алгоритм TD. Например, сложные настольные игры, с которыми у нас нет проблем, выходят за рамки возможностей обучения TD. Кроме того, как я уже намекал ранее, недавние эксперименты показывают, что дофамин кодирует информацию, выходящую далеко за пределы сигнала ошибки TD.
Ничего из этого не должно нас удивлять.
Области мозга, которые симбиотически предсказывают свою среду и друг друга, не ограничиваются простыми алгоритмами обучения или общением с использованием четко определяемых математических переменных, так же как человеческое эмоциональное выражение не сводится к одной единственной измеримой величине, а естественный язык не ограничивается логической грамматикой. Как и любой другой подход к машинному обучению, описанный в этой книге, обучение с подкреплением (TD learning) является элегантным концептуальным упрощением, которое проливает свет, но не освещает каждую его грань. Это ни полное, ни точное представление того, что делает мозг.
В 2016 году модель AlphaGo от DeepMind попала в заголовки новостей, достигнув значительного рубежа в истории ИИ. Эта программа, основанная на более сложном потомке TD обучения (который мы рассмотрим в главе 5), одержала победу над действующим чемпионом по го Ли Седолем в четырех из пяти партий.
Эти новости появились на фоне сообщений о том, что машинное обучение превосходит людей в стремительно растущем списке задач, которые ранее считались «безопасно» выходящими за пределы возможностей ИИ.
▶ Ли Седол реагирует на 37-й ход AlphaGo во второй партии их пятиматчевого противостояния в Сеуле 10 марта 2016 года; Kohs 2017.
Несмотря на это впечатляющее достижение, нейрофилософ Патрисия Чёрчленд указала на фундаментальные ограничения парадигмы ИИ по сравнению с тем, что делают реальные организмы с реальными мозгами. В ответ на победу AlphaGo Чёрчленд написала эссе под названием «Мотивации и побуждения — это вычислительно запутанные вещи», отметив:
«Несмотря на успех [искусственных нейронных сетей, таких как AlphaGo], их поведение сильно отличается от того, что может сделать крыса или человек […]. Поддержание гомеостаза часто связано с конкурирующими ценностями и возможностями, а также с компромиссами и приоритетами […]: следует ли мне спариваться или прятаться от хищника, есть или спариваться, сражаться или бежать, отступить в этой борьбе или продолжать сражение […]. Основная нейронная схема для большинства из этих решений понятна, если вообще понятна, то лишь в самых общих чертах».
И они действительно предполагают некое чувство «я» […]. Это правда. Чисто основанный на методах обучения с подкреплением подход, каким бы изощренным ни был алгоритм, не может объяснить реалистичное поведение животных, потому что настоящие животные — включая нас — не оптимизируют свои действия для достижения какой-то одной цели (разве что, может быть, когда мы играем в го на чемпионатном уровне). Однако «настоящий ИИ» может оказаться проще, чем предполагали Черчленд или кто-либо из нас в 2016 году.
Существуют близкие математические связи между различными известными методами машинного обучения, и продолжающаяся теоретическая работа, вероятно, еще больше их объединит. Хотя это остается активной областью исследований, я верю, что единая теория обучения в конечном итоге охватит эволюцию, мозги и, как частные случаи, устоявшиеся методы машинного обучения. Такое объединение позволит: - Сформулировать центральную задачу как активное предсказание будущего на основе прошлого; - Не различать обучение и оценку или вывод, а вместо этого признать, что предсказание должно происходить на всех временных масштабах; - Синтезировать предсказание с расширенной теорией термодинамики в духе динамической стабильности, как это было описано для бактерий в главе 2; - Объяснить, как взаимное предсказание между агентами может привести к коллективным, не нулевым результатам.
Единая теория освещала бы глубокие связи между вычислениями, машинным обучением, нейронаукой, эволюцией и термодинамикой. Такая теория еще не завершена, но эта книга предлагает представление о том, как она может выглядеть, основываясь на гипотезе о том, что природа делает на каждом уровне, от клеток (и ниже) до обществ: предсказание последовательностей без надзора.
Предсказанные последовательности предполагают продолжение существования. Если бы это не так, то организмы, которые делали бы такие (самосаботирующиеся) предсказания, не остались бы здесь. Более того, как мы вскоре увидим, когда сущности, способные воспринимать друг друга, начинают взаимно предсказывать друг друга, им становится легко вступить в симбиотическое партнерство, в котором их совместное будущее существование более безопасно, чем их индивидуальные жизни.
Давайте назовем эту точку зрения «динамически стабильным симбиотическим предсказанием». Что это будет означать для мозга? В отличие от обучения с подкреплением или любой формы чистого обучения с вознаграждением, симбиотическое предсказание не подразумевает, что животные оптимизируют какое-либо одно вознаграждение, будь то еда или дофамин. Напротив, такая однобокость не способствовала бы ни взаимовыгодным отношениям, ни выживанию в реальном мире, следовательно, она не была бы динамически стабильной. Как отмечает Чёрчленд, «поддержание гомеостаза часто связано с конкурирующими ценностями и возможностями, а также с компромиссами и приоритетами». Это особенно верно в социальных условиях. Существует множество способов существования в этом мире, но все они должны включать в себя продолжение существования в будущем, а существование требует постоянных отношений.
Давайте свяжем эти нити и подытожим: по мере того как эволюция развивалась на основе дизайна простых двусторонних организмов, в головах появились дополнительные нейроны. Это произошло потому, что нейроны сами по себе являются репликаторами, и, как все репликаторы, они будут колонизировать любую благоприятную нишу, особенно когда такое нейронное размножение симбиотически помогает всему организму. Как только этот «мозговой узел» начал расти, развивались более сложные нейронные сети, способные обрабатывать более сложные сенсорные модальности, такие как слух и зрение в стиле камеры. С помощью нейромодуляторных сигналов, таких как дофамин, такие мозги также смогли предсказывать все более тонкие паттерны, имеющие значение для всего организма, на все более длительных временных интервалах.
Таким образом, животные приобрели вычислительную мощность для разработки поведенчески значимых моделей других сложных животных, что привело к ранним «взрывам социальной интеллекта», очевидным в кембрийский период. В 2017 году, в разгаре популярности свёрточных нейронных сетей, вышел эпизод painfully accurate комедийного сериала «Силиконовая долина», который касался приложения «Не хот-дог», полностью эквивалентного моему сценарию здесь; Seppala 2017. Я просто стремлюсь к более здоровому меню.
В математике активация нейрона-банана представляет собой скалярное произведение его векторного веса входа и векторного представления.
С функцией softmax эта инвариантность лишь приблизительна; изменение «банановости» слоя встраивания все равно немного повлияет на выходные данные. Эта особенность важна для работы обратного распространения ошибки; нейронная сеть не сможет обучаться, если не будет способа определить, улучшает ли изменение весов результат или ухудшает.
В математике применение последовательности линейных преобразований эквивалентно применению одного линейного преобразования: A(Bx) = (AB)x. Тем не менее, «глубокие линейные сети» могут быть теоретически интересными, особенно для изучения динамики обучения. Saxe, McClelland и Ganguli 2013; Q. Li и Sompolinsky 2021.
Этот теоретический результат справедлив для почти любого типа нелинейности, хотя некоторые нелинейности на практике оказываются гораздо более эффективными, чем другие. За годы было проделано много работы по созданию нелинейностей, которые быстро вычисляются, эффективно обучаются и не «взрываются» численно.
Словосочетание «в принципе» здесь используется, потому что технически линейные преобразования включают как вращение, так и масштабирование.
Техническая заметка: подход к уменьшению размерности, использованный Рефиком, заключался в «стохастическом соседнем встраивании с t-распределением» (t-SNE), что является высоконелинейной операцией, предназначенной для визуализации, а не анализа. Таким образом, линейное (или планарное, или гиперпланарное) разделение впоследствии обычно не сработает, хотя бананы, вероятно, окажутся сгруппированными вместе. Tan и др. 2018.
Это упускает из виду небольшое изменение, которое мы также внесем, чтобы превратить нейрон «не банан» в нейрон «ни банан, ни яблоко», но это незначительная деталь. Qi, Brown и Lowe 2017.
Feingold 1914; Meissner и Brigham 2001.
Tanaka и Pierce 2009.
Buolamwini и Gebru 2018; M. Wang и др. 2019.
Kohl 1993.
Эффект, вероятно, не зависит от того, формируют ли младенцы отдельные звуковые категории с самого начала, как полагал Коль, а скорее от того, что они учатся распознавать неизменные встраивания, представляющие их речевую среду; Фельдман и др. 2021 ↩ . В более точном математическом языке они показывают, что хотя конкретные веса данной сети определяются их случайной инициализацией, эти веса уникальны лишь с учетом произвольного вращения в многомерном пространстве весов на каждом слое; см. Гут и др. 2023; Гут и Менар 2024 ↩ , ↩ . Fairwork 2023; Meaker 2023 ↩ , ↩ . Некоторые детали опущены в этом кратком описании; см. Хе и др. 2021 ↩ . Необъяснимо, но наши сетчатки устроены «задом наперед», с проводкой перед фоточувствительными клетками — почти доказательство отсутствия разумного дизайна. Сетчатки осьминогов, которые эволюционировали независимо, устроены правильно, с сенсорами света на переднем плане. Эти эксперименты рассмотрены в работе Чёрчленда, Рамачандрана и Сейновского 1994 ↩ . Такие записи редки; они делаются, когда нейрохирурги пытаются выяснить, как лучше всего провести операцию на мозге пациента, при этом сохраняя как можно больше функций. Исследователи собирают ценные данные о человеке такого рода, когда могут, но любые научные цели всегда вторичны по отношению к клиническим. Хантер, Спраклен и Ахмад 2022 ↩ . Курц и др. 2020; Ли и др. 2022 ↩ , ↩ . Цю, Хуан и Фу 2023 ↩ . Гросс 2002 ↩ . Куирога и др. 2005 ↩ . Дженнифер Энистон и Брэд Питт были женаты с 2000 по 2005 год, так что этому нейрону, возможно, пришлось искать новую работу после их разрыва. Это 128 × 127 × 126 × 125 × 124 × 123 × 122 × 121 × 120 × 119 × 118 × 117 × 116 × 115 × 114 × 113. Исторически эти термины использовались в фехтовании: тот, кто наносит удар, является агентом, а тот, кто получает или страдает от удара, — пациентом.
В истории медицины «пациент» страдает пассивно, пока хирург или врач вскрывает нарывы, делает разрезы для удаления камней, ампутирует конечности, прокалывает вены для кровопускания и проводит другие подобные смелые маневры.
Это также иллюстрирует, почему концепция множественной реализуемости имеет смысл только при наличии конечной цели.
В большинстве случаев на пути есть хотя бы один синапс, но не будем углубляться в анатомические детали.
Strogatz 2004
↩
.
Sarfati et al. 2022
↩
.
Burkhardt et al. 2023
↩
.
H. Wang et al. 2023; Hanson 2023
↩
,
↩
.
Godfrey-Smith 2024
↩
.
Goulty et al. 2023
↩
.
Heath 1963
↩
.
Berridge and Robinson 1998
↩
.
Gershman et al. 2024
↩
.
Zénon, Devesse, and Olivier 2016
↩
.
Achatz et al. 2013
↩
.
Они также занимаются «фехтованием пенисами». Поиск в Google, если вы чувствуете себя смелым.
Raz et al. 2017
↩
.
Местная адаптация также приводит к слабым формам обучения, известным как «сенсибилизация» и «габитуция». Cheng 2021
↩
.
Связано с этим, J. J. Moore et al. 2024
↩
предлагают, что отдельные нейроны могут действовать как оптимальные контроллеры обратной связи.
R. R. Bush и Mosteller 1951; Rescorla и Wagner 1972
↩
,
↩
.
Sutton 1988
↩
.
Sutton 1988
↩
, выделение моё.
Tesauro 1992, 1994
↩
,
↩
.
Для всестороннего исторического обзора развития обучения с подкреплением и его сближения с исследованиями дофамина см. Colombo 2014
↩
.
Romo и Schultz 1990
↩
.
Montague, Dayan и Sejnowski 1996
↩
.
Исходные эксперименты проводились с приматами, но доказательства указывают на то, что дофамин играет аналогичную роль, опосредованную теми же структурами мозга, у всех позвоночных. Аналогичные системы, включающие родственные нейромодуляторные химические вещества, также, похоже, эволюционировали у беспозвоночных. Mizunami и Matsumoto 2017
↩
.
Fouragnan, Retzler и Philiastides 2018; Diederen и Fletcher 2021
↩
,
↩
.
C.-S. Lee et al. 2016
↩
.
Shoham et al. 2017
↩
.
Churchland 2016
↩
.
Например, Sutton 1988
↩
описывает, как обучение с подкреплением и контролируемое обучение могут быть поняты как методы градиентного спуска для предсказания последовательностей.
Сегодняшнее разделение обработки вывода (обычно связанного с короткими временными интервалами), так называемой «адаптации» (промежуточные временные интервалы) и обучения (долгосрочные временные интервалы) является артефактом кибернетической формализации, описанной в главе 3 «Отрицательная обратная связь».
Керамати и Гуткин 2011; Лоренсон и др. 2024
↩
↩
См. главу 1 «Комплексфикация».
Другие умы